Case Study Sobel
This design example shows how to build a line buffer filter that works at the full bandwidth the memory system can provide. The filter itself is separable, allowing the computation to be split into three pipelined stage: first the horizontal kernel, then the vertical filter, and finally clipping.
This case study is located in $HLD_ROOT/design-examples/sobel.
In this example we need to perform SIMD operations on cacheline-sized blocks every cycle if we are going to achieve maximum bandwidth. Since we will be working with different datatypes at different stages of the pipeline, we will take advantage of template parameterization in C++. So instead of defining three user types like this:
#!/usr/bin/env python3
from cog_acctempl import *
dut = DUT("sobel")
dut.add_ut( UserType("BlkInp",[ArrayField(UnsignedCharField("data"),64)]))
dut.add_ut( UserType("BlkOut",[ArrayField(SignedCharField("data"),64)]))
dut.add_ut( UserType("BlkMid",[ArrayField(SignedShortField("data"),64)]))we'll generate just one of them, using a more generic name such as Blk, using this simple dut_params.py skeleton:
#!/usr/bin/env python3
from cog_acctempl import *
dut = DUT("sobel")
dut.add_ut( UserType("Blk",[ArrayField(UnsignedCharField("data"),64)]))
Since we need to add SIMD operator functions and methods to these classes, which are identical except for different element data types, we will instead just generate one generic usertype and produce the element type specific version by instantiating the generic class.
By parameterizing Blk with an element type T and a block size N, we can produce the other types by:
typedef Blk<unsigned char,64> BlkInp;
typedef Blk<short ,64> BlkMid;
typedef Blk<char ,64> BlkOut;
Normally we would use this dut_params.py and run $HLD_ROOT/scripts/systemc-gen/gen-all-usertypes.py (remember to set PYTHONPATH) to generate our description for Blk.h. However, since we are building a generic class, we will not be needing the cog-based generator code later so let's remove it from the very beginning. Instead, generate Blk.h using:
cog.py -d -I. -Dty=Blk -I$HLD_ROOT/scripts/systemc-gen/ -o Blk.h $HLD_ROOT/scripts/systemc-gen/Usertype-cog.h
This produces:
//ty=Blk
#ifndef Blk_H_
#define Blk_H_
#ifndef __SYNTHESIS__
#include <cstddef>
#include <cassert>
#endif
class Blk {
public:
unsigned char data[64];
enum { ArrayLength = 64 };
typedef unsigned char ElementType;
enum { BitCnt = 512 };
static size_t getBitCnt() {
assert(sizeof(Blk) == (size_t) BitCnt/8);
assert( 0 == (size_t) BitCnt%8);
return BitCnt;
}
static size_t numberOfFields() {
return 64;
}
static size_t fieldWidth( size_t index) {
if ( 0 <= index && index < 64) {
return 8;
}
return 0;
}
void putField(size_t index, UInt64 d) {
if ( 0 <= index && index < 64) {
data[index-0] = d;
}
}
UInt64 getField(size_t index) const {
if ( 0 <= index && index < 64) {
return data[index-0];
}
return 0;
}
#if !defined(__AAL_USER__) && !defined(USE_SOFTWARE)
inline friend void sc_trace(sc_trace_file* tf, const Blk& d, const std::string& name) {
}
#endif
inline friend std::ostream& operator<<(std::ostream& os, const Blk& d) {
os << "<Blk>";
return os;
}
inline bool operator==(const Blk& rhs) const {
bool result = true;
for( unsigned int i=0; i<numberOfFields(); ++i) {
result = result && (getField(i) == rhs.getField(i));
}
return result;
}
};
#endifWe will now generalize this to work with any element type and block size.
#ifndef Blk_H_
#define Blk_H_
#ifndef __SYNTHESIS__
#include <cstddef>
#include <cassert>
#endif
template<typename T, int N>
class Blk {
public:
T data[N];
enum { ArrayLength = N };
typedef T ElementType;
enum { BitCnt = 8*sizeof(T)*N };
static size_t getBitCnt() {
assert(sizeof(Blk) == (size_t) BitCnt/8);
assert( 0 == (size_t) BitCnt%8);
return BitCnt;
}
static size_t numberOfFields() {
return N;
}
static size_t fieldWidth( size_t index) {
return 8*sizeof(T);
}
void putField(size_t index, UInt64 d) {
data[index] = d;
}
UInt64 getField(size_t index) const {
return data[index];
}
#if !defined(__AAL_USER__) && !defined(USE_SOFTWARE)
inline friend void sc_trace(sc_trace_file* tf, const Blk<T,N>& d, const std::string& name) {
}
#endif
inline friend std::ostream& operator<<(std::ostream& os, const Blk<T,N>& d) {
os << "<Blk>";
return os;
}
inline bool operator==(const Blk& rhs) const {
bool result = true;
for( unsigned int i=0; i<numberOfFields(); ++i) {
result = result && (getField(i) == rhs.getField(i));
}
return result;
}
};
#endifNext we add SIMD functions and an initializing constructor, all inside the class definition of Blk:
Blk() {} // the default constructor should not initialize the array
Blk( const T& elem) {
UNROLL_INITIALIZE_BLK:
for( unsigned int i=0; i<N; ++i) {
data[i] = elem;
}
}
inline friend Blk<T,N> operator+( const Blk<T,N>& a, const Blk<T,N>& b) {
Blk result;
UNROLL_SUM:
for( unsigned int i=0; i<N; ++i) {
result.data[i] = a.data[i] + b.data[i];
}
return result;
}
inline friend Blk<T,N> operator*( const Blk<T,N>& a, const T& k) {
Blk result;
UNROLL_PRODUCT:
for( unsigned int i=0; i<N; ++i) {
result.data[i] = a.data[i] * k;
}
return result;
}The remainder of dut_params.py generates the module and process structure as well as the communication channels:
#!/usr/bin/env python3
from cog_acctempl import *
dut = DUT("sobel")
dut.add_ut( UserType("BlkInp",[ArrayField(UnsignedCharField("data"),64)]))
dut.add_ut( UserType("BlkOut",[ArrayField(SignedCharField("data"),64)]))
dut.add_ut( UserType("BlkMid",[ArrayField(SignedShortField("data"),64)]))
dut.add_rd( TypedRead( "BlkInp", "inp", "__inp_Slots__", "1<<24", "1"))
dut.add_wr( TypedWrite("BlkOut","out"))
dut.add_extra_config_fields( [UnsignedIntField("nInp"),
UnsignedIntField("num_of_rows"),
UnsignedIntField("row_size_in_blks"),
UnsignedIntField("image_size_in_bytes"),
UnsignedIntField("num_of_images")])
dut.add_storage_fifo( StorageFIFO( "BlkMid", 2, "mid0"))
dut.add_storage_fifo( StorageFIFO( "BlkMid", 2, "mid1"))
dut.add_module( Module("sobel_frontend"))
dut.add_module( Module("sobel_backend"))
dut.add_module( Module("sobel_restrict"))
dut.add_cthread( CThread("out_addr_gen"))
dut.add_cthread( CThread("inp_addr_gen"))
dut.get_module("sobel_frontend").add_cthread( CThread("deltax"))
dut.get_module("sobel_backend").add_cthread( CThread("deltay"))
dut.get_module("sobel_restrict").add_cthread( CThread("clip",writes_to_done=1))
dut.get_cthread( "inp_addr_gen").add_port( RdReqPort("inp"))
dut.get_cthread( "deltax").add_port( RdRespPort("inp"))
dut.get_cthread( "deltax").add_port( EnqueuePort( "mid0"))
dut.get_cthread( "deltay").add_port( DequeuePort( "mid0"))
dut.get_cthread( "deltay").add_port( EnqueuePort( "mid1"))
dut.get_cthread( "out_addr_gen").add_port( WrReqPort("out"))
dut.get_cthread( "clip").add_port( WrDataPort("out"))
dut.get_cthread( "clip").add_port( DequeuePort( "mid1"))
if __name__ == "__main__":
dut.dump_dot( dut.nm + ".dot")
There are two address generation threads at the top level, one for the inp memory read interface and one for the out memory write interace. There are then three modules defining the processing pipeline. Each module (separately compilable in CtoS and Quartus) contains exactly one thread. There are also two internal fifos (mid0 and mid1) defined at the top-level to specify the connectivity.
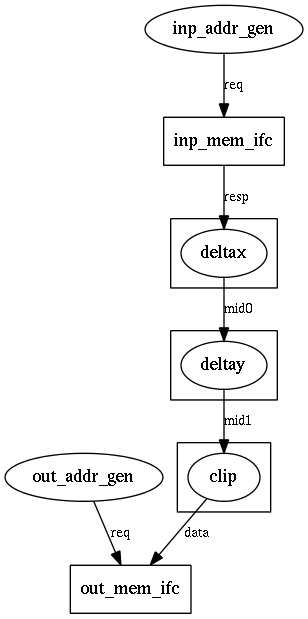
After we generate the usertypes (running gen-all-usertypes.py), we will get BlkInp.h, BlkMid.h, and BlkOut.h generated in the usual manner. Simply replace them with an include of Blk.h and a declaration the appropriate typedef. If you later regenerate the usertypes, gen-all-usertypes.py will use your custom code for these usertypes. (This is because the script will use an existing file [instead of the common template] and because running cog on a file without generators will return the same file.) Here are the complete modified files:
#ifndef BlkInp_H_
#define BlkInp_H_
#include "Blk.h"
typedef Blk<unsigned char,WORDS_PER_BLK> BlkInp;
#endif
#ifndef BlkMid_H_
#define BlkMid_H_
#include "Blk.h"
typedef Blk<short,WORDS_PER_BLK> BlkMid;
#endif
#ifndef BlkOut_H_
#define BlkOut_H_
#include "Blk.h"
typedef Blk<char,WORDS_PER_BLK> BlkOut;
#endif
As for the threads, let's start with the third module (sobel_restrict) and its single thread (clip). This process clips the 16-bit signed values produced by the earlier stages of the pipeline to 8-bit signed values for output. The image is traversed in left-to-right and then top-to-bottom order. Image width must be a multiple of words_per_blk. This value, bpr (blocks per row,) is specified in the Config class. The number of rows, ni, in the image is as well. This is accomplished by incrementing jc (the blocks in the row) and ip (the rows in the images), checking if the end of the row is hit (and then reseting jc) and asserting done when the complete image has been processed.
void clip() {
outDataOut.reset_put(); // type: MemTypedWriteDataType<BlkOut>
mid1.reset_get(); // type: BlkMid
Int16 ip = 0;
Int16 jc = 0;
done = false;
wait();
while (1) {
if ( start) {
Int16 ni = config.read().get_num_of_rows();
Int16 bpr = config.read().get_row_size_in_blks();
const unsigned int words_per_blk = BlkMid::ArrayLength;
const BlkOut::ElementType min_rep = std::numeric_limits<BlkOut::ElementType>::min();
const BlkOut::ElementType max_rep = std::numeric_limits<BlkOut::ElementType>::max();
BlkMid icl = mid1.get();
BlkOut ocl;
for( unsigned int k=0; k<words_per_blk; ++k) {
BlkOut::ElementType r;
if ( icl.data[k] < min_rep) {
r = min_rep;
} else if ( icl.data[k] > max_rep) {
r = max_rep;
} else {
r = icl.data[k];
}
ocl.data[k] = r;
}
outDataOut.put( ocl);
++jc;
if ( jc >= bpr) {
jc = 0;
++ip;
if ( ip == ni) {
done = true;
ip = 0;
}
}
}
wait();
}
}Now let's look at the first module (sobel_frontend) with the single process (deltax). Here we are convolving each line with a five element kernel. Two values from the next block and two values from the previous block are required from correct computation. The left variable stores the previous va
void deltax() {
inpRespIn.reset_get(); // type: MemTypedReadRespType<BlkInp>
mid0.reset_put(); // type: BlkMid
const unsigned int bj = 2;
const unsigned int words_per_blk = BlkInp::ArrayLength;
const short kr[1][2*bj+1] = { {1,2,0,-2,-1} };
BlkInp lastcl;
BlkInp::ElementType left[bj];
UInt16 ip = 0;
UInt16 jc = 0;
bool do_final = false;
wait();
while (1) {
if ( start) {
UInt16 ni = config.read().get_num_of_rows();
UInt16 bpr = config.read().get_row_size_in_blks();
BlkInp cl;
if (!do_final) {
cl = inpRespIn.get().data;
}
// combinational
BlkInp::ElementType right[bj];
UNROLL_INITIAL_RIGHT:
for( unsigned int k=0; k<bj; ++k) {
right[k] = 0;
}
if ( do_final) {
} else if ( ip == 0 && jc == 0) {
} else if ( ip > 0 && jc == 0) {
} else {
UNROLL_RIGHT_C:
for( unsigned int k=0; k<bj; ++k) {
right[k] = cl.data[k];
}
}
if ( ip == 0 && jc == 0) {
} else {
BlkInp::ElementType buf[bj+words_per_blk+bj];
UNROLL_BUF_A:
for ( unsigned int k=0; k<bj; ++k) {
buf[k] = left[k];
}
UNROLL_BUF_B:
for ( unsigned int k=0; k<words_per_blk; ++k) {
buf[bj+k] = lastcl.data[k];
}
UNROLL_BUF_C:
for ( unsigned int k=0; k<bj; ++k) {
buf[bj+words_per_blk+k] = right[k];
}
BlkMid newlastcl(0);
UNROLL_SUM:
for( unsigned int jj=1; jj<bj+1; ++jj) {
UNROLL_NEWLASTCL:
for( unsigned int k=0; k<words_per_blk; ++k) {
newlastcl.data[k] += (BlkMid::ElementType) buf[bj-jj+k] * kr[0][bj-jj];
newlastcl.data[k] += (BlkMid::ElementType) buf[bj+jj+k] * kr[0][bj+jj];
}
}
mid0.put( newlastcl);
}
if ( ip == 0 && jc == 0) {
UNROLL_LEFT_A:
for( unsigned int k=0; k<bj; ++k) {
left[k] = 0;
}
} else if ( ip > 0 && jc == 0) {
UNROLL_LEFT_B:
for( unsigned int k=0; k<bj; ++k) {
left[k] = 0;
}
} else {
UNROLL_LEFT_C:
for( unsigned int k=0; k<bj; ++k) {
left[k] = lastcl.data[words_per_blk-bj+k];
}
}
lastcl = cl;
if ( do_final) {
ip = 0;
jc = 0;
do_final = 0;
} else {
++jc;
if ( jc >= bpr) {
jc = 0;
++ip;
if ( ip == ni) {
do_final = 1;
}
}
}
}
wait();
}
}Finally, the second module in the pipeline (sobel_backend) with the single process (deltay):
void deltay() {
mid0.reset_get(); // type: BlkMid
mid1.reset_put(); // type: BlkMid
UInt16 ip = 0;
UInt16 jc = 0;
UInt16 jc_last;
const unsigned int MAXBPR = 40 * 64 / BlkMid::ArrayLength;
BlkMid d0[MAXBPR];
BlkMid d1[MAXBPR];
BlkMid d2[MAXBPR];
BlkMid d3[MAXBPR];
BlkMid cl;
BlkMid d0_buf;
BlkMid d1_buf;
BlkMid d2_buf;
BlkMid d3_buf;
wait();
while (1) {
if ( start) {
UInt16 ni = config.read().get_num_of_rows();
UInt16 bpr = config.read().get_row_size_in_blks();
const unsigned int bi = 2;
const short kl[2*bi+1][1] = { {1}, {4}, {6}, {4}, {1}};
if ( ip == 0 && jc == 0) {
jc_last = bpr-1;
}
if ( ip == 0 || ip < ni) {
cl = mid0.get();
}
if (ip >= ni) {
mid1.put( d0[jc]);
} else if (ip >= bi) {
mid1.put( d0[jc] + cl*kl[4][0]);
}
BlkMid z = BlkMid( 0);
d0[jc_last] = d0_buf;
d0_buf = ((ip<ni) ? cl*kl[3][0] : z) + ((ip> 0) ? d1[jc] : z);
d1[jc_last] = d1_buf;
d1_buf = ((ip<ni) ? cl*kl[2][0] : z) + ((ip> 0) ? d2[jc] : z);
d2[jc_last] = d2_buf;
d2_buf = ((ip<ni) ? cl*kl[1][0] : z) + ((ip> 0) ? d3[jc] : z);
d3[jc_last] = d3_buf;
d3_buf = ((ip<ni) ? cl*kl[0][0] : z);
jc_last = jc;
++jc;
if ( jc == bpr) {
++ip;
jc = 0;
if ( ip == ni+bi) {
ip = 0;
}
}
}
wait();
}
}This code uses an anti-dependency style for specifing the pipelined register file accesses.