Case Study Multi threaded Cycle Detection
In this example, we show how to hide long latency read responses by multi-threading a computation. We use the example shown in the lab, but modify it so that cycle detection is performed from many different starting pointers (instead of just one.) The algorithm has been attributed to Floyd.
This case study is located in the directory $HLD_ROOT/tutorials/multi-linkedlist
We generate pointer structures with 2*n nodes, and perform m cycle detection problem instances. The m instances are specified using an array of m pointers. The results are written into another array (in an arbitrary order) where the least significant bit of the pointer value is set if the pointer is in a cycle.
For convenience in testing, the first n nodes are all in a cycle of size 1 << logG (where logG = 6), while the second n nodes are not in a cycle. The starting pointer values are randomly assigned from all 2*n nodes.
We use this dut_params.py file:
#!/usr/bin/env python3
from cog_acctempl import *
dut = DUT("linkedlist")
dut.add_ut( UserType("HeadPtr",[UnsignedLongLongField("head")]))
dut.add_ut( UserType("Node",[UnsignedLongLongField("next"),
UnsignedLongLongField("val")]))
dut.add_rds( [SingleRead("Node","State","lst","__lst_Slots__")])
dut.add_rds( [TypedRead("HeadPtr","inp","__inp_Slots__","1 << 30","1")])
dut.add_wrs( [TypedWrite("HeadPtr","out")])
dut.add_extra_config_fields( [UnsignedLongLongField("m")])
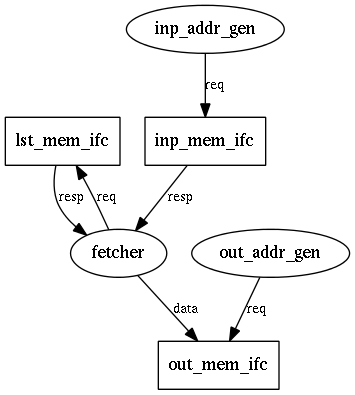
dut.module.add_cthreads( [CThread("fetcher",ports=[RdRespPort("inp"),
WrDataPort("out"),
RdReqPort("lst"),
RdRespPort("lst")],
writes_to_done=True),
CThread("inp_addr_gen",ports=[RdReqPort("inp")]),
CThread("out_addr_gen",ports=[WrReqPort("out")])])
dut.semantic()
if __name__ == "__main__":
dut.dump_dot( dut.nm + ".dot")There are two user types: HeadPtr holds a pointer to objects of type Node and Node objects also contain a Node pointer along with a value field. We represent pointers as bare 64-bit unsigned long long data. Convenience methods will be added to convert these to pointers allowing more natural dereferencing in testbench code.
We use the memory type SingleRead which requires a second class name corresponding to tag data sent along with the address to request a memory read. This tag data will be returned along with the corresponding read response. That class does not need marshalling code so we define it manually (with using the cog template system.)
For this example, we will change the actual generator code for Config.h.
We do this to avoid generating the unnecessary base pointer of the lst memory port. Initial generation of Config.h produces:
/*[[[cog
import cog
from cog_acctempl import *
from dut_params import *
]]]*/
//[[[end]]] (checksum: d41d8cd98f00b204e9800998ecf8427e)
#ifndef __CONFIG_H__
#define __CONFIG_H__
...Within the cog block, add this definition of the variable ports:
...
from dut_params import *
ports = [ x for x in dut.inps + dut.outs if x.nm != "lst"]
]]]*/
...This list now contains all the memory port names except "lst".
Now, modify all later usages of collection dut.inps + dut.outs with this new variable ports. For example,
/*[[[cog
for p in dut.inps + dut.outs:
cog.outl("AddrType a%s : 64;" % p.nm.capitalize())
]]]*/should become:
/*[[[cog
for p in ports:
cog.outl("AddrType a%s : 64;" % p.nm.capitalize())
]]]*/(Make this change for all occurrences of dut.inps + dut.outs in the file.)
Now, field definitions and member functions associated with "lst" are not generated.
In the generated code for HeadPtr.h, we want to add helper code to converter the raw data type to the pointer Node *.
This code:
/*[[[cog
cog.outl("class %s {" % ty)
]]]*/
class HeadPtr {
//[[[end]]] (checksum: 2a12d540710fb84903aa2bc1f473096b)
public:
/*[[[cog
for field in ut.fields:
cog.outl( field.declaration)
]]]*/
unsigned long long head;
//[[[end]]] (checksum: 511a18547689ac7fdd1d52227f83ec8b)can be changed to:
class Node;
/*[[[cog
cog.outl("class %s {" % ty)
]]]*/
class HeadPtr {
//[[[end]]] (checksum: 2a12d540710fb84903aa2bc1f473096b)
public:
/*[[[cog
for field in ut.fields:
cog.outl( field.declaration)
]]]*/
unsigned long long head;
//[[[end]]] (checksum: 511a18547689ac7fdd1d52227f83ec8b)
Node *get_head() const {
return reinterpret_cast<Node *>( head);
}
void set_head( Node *node) {
head = reinterpret_cast<unsigned long long>( node);
}
bool get_found() const {
return head & 0x1ULL;
}
void set_found( bool val) {
if ( val) {
head = head | 0x1ULL;
} else {
head = head & ~0x1ULL;
}
}Here we have inserted a forward reference to the Node class, and also member functions: to get and set the pointer, using Node * instead of unsigned long long, and to get and set the result bit (LSB).
We add one member function the the Node class:
//[[[end]]] (checksum: 37cbdab3d21a741c7433cfde5e2d2c4f)
void set_next( Node* node) {
next = reinterpret_cast<unsigned long long>( node);
}
/*[[[cogThis simplifies the testbench code that generates the initial list data.
We also add the following code to linkedlist_hls.h:
...
#ifndef __inp_Slots__
#define __inp_Slots__ 128
#endif
#ifndef __lst_Slots__
#define __lst_Slots__ 128
#endif
#include "Config.h"
class State {
public:
HeadPtr head;
HeadPtr fast;
HeadPtr slow;
unsigned char state;
State() {
head.head = fast.head = slow.head = state = 0;
}
friend std::ostream& operator<<( std::ostream& os, const State& s) {
return os << "State(" << s.head.head << "," << s.fast.head << "," << s.slow.head << "," << s.state;
}
bool operator==( const State& s) const {
return head == s.head && fast == s.fast && slow == s.slow && state == s.state;
}
};
...This code defines the two tuning parameters __inp_Slots__ and __lst_Slots__ as well as the class State that defines the tag data used by SingleRead. The class storage the state for each thread. This includes the starting pointer head, the fast and slow pointers used in the algorithm, and an unsigned char representing, in essence, the program counter of the thread.
The SystemC required operator<< and operator== are added as well.
The two address generation threads are similar the those described in the memcpy and vectoradd tutorials and won't be discussed further here.
The remaining thread corresponds to the main computation. Removing the generation code, we get:
void fetcher() {
inpRespIn.reset_get(); // type: MemTypedReadRespType<HeadPtr>
outDataOut.reset_put(); // type: MemTypedWriteDataType<HeadPtr>
lstReqOut.reset_put(); // type: MemSingleReadReqType<Node,State>
lstRespIn.reset_get(); // type: MemSingleReadRespType<Node,State>
unsigned long long ip = 0;
unsigned int slack = __lst_Slots__;
done = false;
wait();
while (1) {
if ( start) {
if ( ip != config.read().get_m()) {
if ( slack > 0 && inpRespIn.nb_can_get()) {
MemTypedReadRespType<HeadPtr> resp;
inpRespIn.nb_get( resp);
slack -= 1;
State state;
state.head = resp.data;
state.fast = state.head;
state.slow = state.head;
if ( state.fast.head) {
state.state = 1;
lstReqOut.put( MemSingleReadReqType<Node,State>( state.fast.head, state));
} else {
outDataOut.put( MemTypedWriteDataType<HeadPtr>( state.head));
slack += 1;
++ip;
}
} else if ( lstRespIn.nb_can_get()) {
MemSingleReadRespType<Node,State> resp;
lstRespIn.nb_get( resp);
State state = resp.utag;
if ( state.state == 1) {
state.fast.head = resp.data.next;
if ( !state.fast.head) {
outDataOut.put( MemTypedWriteDataType<HeadPtr>( state.head));
slack += 1;
++ip;
} else if ( state.fast.head == state.slow.head) {
state.head.set_found( 1);
outDataOut.put( MemTypedWriteDataType<HeadPtr>( state.head));
slack += 1;
++ip;
} else {
state.state = 2;
lstReqOut.put( MemSingleReadReqType<Node,State>( state.slow.head, state));
}
} else if ( state.state == 2) {
state.slow.head = resp.data.next;
state.state = 3;
lstReqOut.put( MemSingleReadReqType<Node,State>( state.fast.head, state));
} else if ( state.state == 3) {
state.fast.head = resp.data.next;
if ( state.fast.head) {
state.state = 1;
lstReqOut.put( MemSingleReadReqType<Node,State>( state.fast.head, state));
} else {
outDataOut.put( MemTypedWriteDataType<HeadPtr>( state.head));
slack += 1;
++ip;
}
} else {
assert(0);
}
}
} else {
done = true;
}
}
wait();
}
}We add two variables: ip which counts the number of cycle detection 'problems' we are solving, and slack which keeps track of how many more in-flight memory reads are possible. This value is initialized to __lst_Slots__, the number of storage buffers for reads through the lst memory interface.
In the main loop, we continue until we have done all m 'problems', first checking to see if: 1) we have space to add a new 'problem' (slack > 0) and 2) a new 'problem' is availiable (inpRespIn.nb_can_get()). If so, we add a new 'problem' by getting the head pointer from the input array, decrementing the slack variable, initializing a State object, performing the first step of the algorithm (which either concludes that there is no cycle [initial head pointer is null] or injects a thread into the pool by performing a memory read from address state.fast.head and tag state.)
If we can't inject a new thread, then we see if an old thread is available for processing (lstRespIn.nb_can_get()). If so, we, based on the value of state.state in this thread, perform the next step of the algorithm, which will either complete the thread computation with a cycle detected or cycle not detected value, or cause the thread to modified and a new memory read performed.
Here is the mapping of the original software algorithm to the states specified here:
int cycle_detect(Node *head) {
Node *fast = head;
Node *slow = head;
while( fast) {
fast = fast->next; //State 0->1 and 3->1
if(!fast) {
return 0; //State 1
}
if(fast == slow) {
return 1; //State 1
}
slow = slow->next; //State 1->2
fast = fast->next; //State 2->3
}
return 0;
}With enough slots, full memory bandwidth can be achieved because instead of idly waiting for the memory system to return responses, we use the same hardware to solve a separate cycle detection instance.
(The custom code for scheduling multi-AFUs is similar to that in the previous tutorials.)
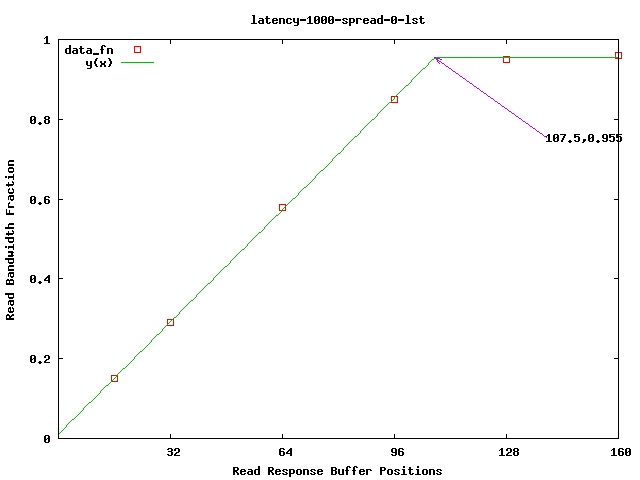
There are two queue sizes in this example: the number of slots in the the random single request read port named __lst_Slots__ and the streaming read port __inp_Slots__. The value of __inp_Slots__ is not likely to be too important because: 1) we take multiple cycles to process a single input value, and 2) there are multiple head pointers per cache line (8 64-bit values.)
So we'll set __inp_Slots__ to a very high value (say 32) and sweep the other parameter, __lst_Slots__.
Using the bash script:
#!/bin/bash
for slots in 16 32 64 96 128 160
do
echo "Compiling ${slots}..."
cd acc_build
make clean
make __lst_Slots__=${slots} __inp_Slots__=32
echo "Running ${slots}..."
./acc_test > LOG-${slots}
cd -
done
We need to parameterize the Makefile as well in the acc_build subdirectory:
...
ifdef __inp_Slots__
CFLAGS += -D__inp_Slots__=$(__inp_Slots__)
endif
ifdef __lst_Slots__
CFLAGS += -D__lst_Slots__=$(__lst_Slots__)
endif
...
Performing the design experiment and graphing the results as described here, we see that ~128 slots will achieve maximum bandwidth.
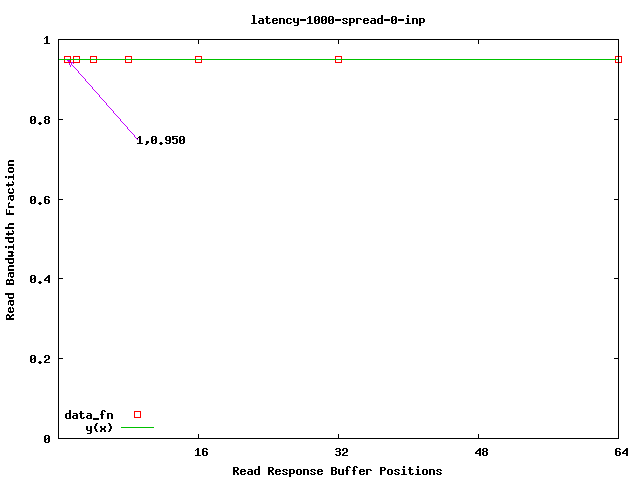
At this point we can determine a appropriate value for __inp_Slots__ by sweeping its value given a fixed value of 128 for __lst_Slots__.
The graph below shows that 1 is enough to achieve maximum bandwidth. (This will depend on the length of the paths traversed in the various problem instances.)