-
Notifications
You must be signed in to change notification settings - Fork 2.6k
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
[Project] Medical semantic seg dataset: ISIC-2016 Task1 (#2708)
- Loading branch information
1 parent
78e036c
commit b24f422
Showing
7 changed files
with
392 additions
and
0 deletions.
There are no files selected for viewing
149 changes: 149 additions & 0 deletions
149
projects/medical/2d_image/dermoscopy/isic2016_task1/README.md
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,149 @@ | ||
| # ISIC-2016 Task1 | ||
|
|
||
| ## Description | ||
|
|
||
| This project support **`ISIC-2016 Task1 `**, and the dataset used in this project can be downloaded from [here](https://challenge.isic-archive.com/data/#2016). | ||
|
|
||
| ### Dataset Overview | ||
|
|
||
| The overarching goal of the challenge is to develop image analysis tools to enable the automated diagnosis of melanoma from dermoscopic images. | ||
|
|
||
| This challenge provides training data (~900 images) for participants to engage in all 3 components of lesion image analysis. A separate test dataset (~350 images) will be provided for participants to generate and submit automated results. | ||
|
|
||
| ### Original Statistic Information | ||
|
|
||
| | Dataset name | Anatomical region | Task type | Modality | Num. Classes | Train/Val/Test Images | Train/Val/Test Labeled | Release Date | License | | ||
| | ---------------------------------------------------------------- | ----------------- | ------------ | ---------- | ------------ | --------------------- | ---------------------- | ------------ | ---------------------------------------------------------------------- | | ||
| | [ISIC-2016 Task1](https://challenge.isic-archive.com/data/#2016) | full body | segmentation | dermoscopy | 2 | 900/-/379- | yes/-/yes | 2016 | [CC-0](https://creativecommons.org/share-your-work/public-domain/cc0/) | | ||
|
|
||
| | Class Name | Num. Train | Pct. Train | Num. Val | Pct. Val | Num. Test | Pct. Test | | ||
| | :---------: | :--------: | :--------: | :------: | :------: | :-------: | :-------: | | ||
| | background | 900 | 82.08 | - | - | 379 | 81.98 | | ||
| | skin lesion | 900 | 17.92 | - | - | 379 | 18.02 | | ||
|
|
||
| Note: | ||
|
|
||
| - `Pct` means percentage of pixels in this category in all pixels. | ||
|
|
||
| ### Visualization | ||
|
|
||
| 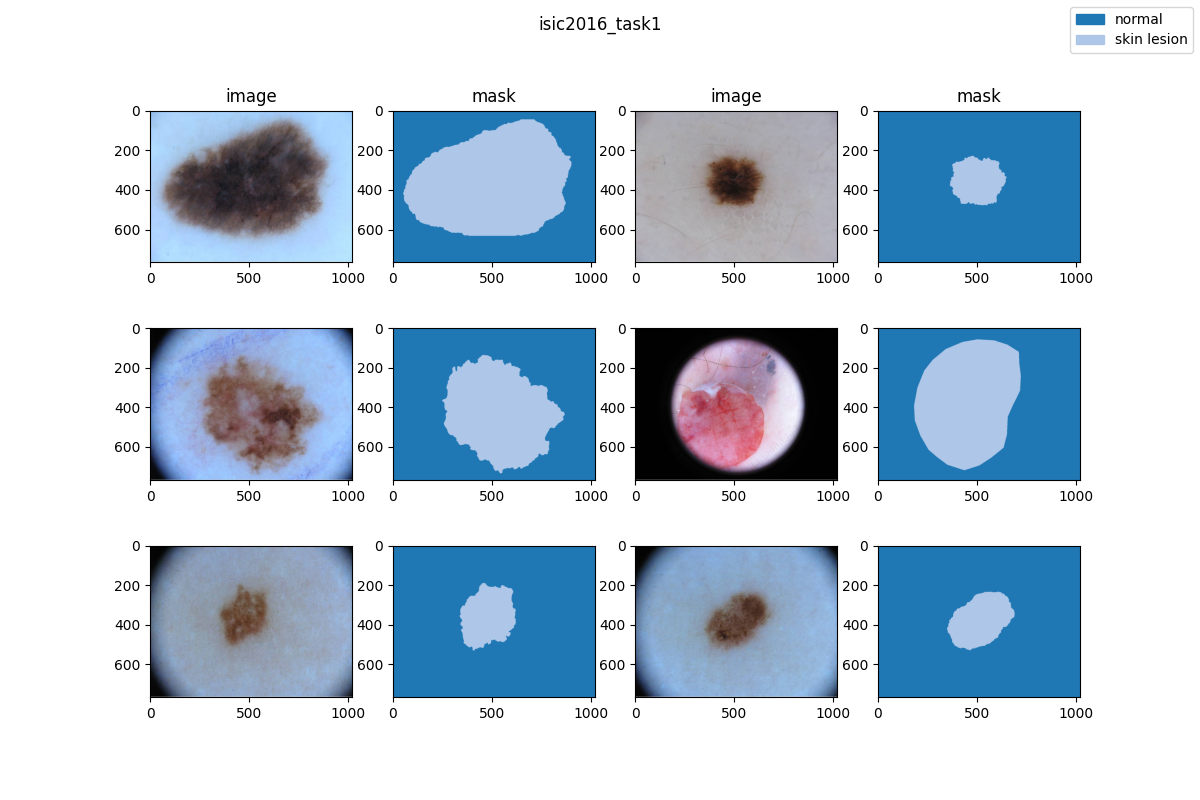 | ||
|
|
||
| ### Prerequisites | ||
|
|
||
| - Python 3.8 | ||
| - PyTorch 1.10.0 | ||
| - pillow(PIL) 9.3.0 | ||
| - scikit-learn(sklearn) 1.2.0 | ||
| - [MIM](https://github.com/open-mmlab/mim) v0.3.4 | ||
| - [MMCV](https://github.com/open-mmlab/mmcv) v2.0.0rc4 | ||
| - [MMEngine](https://github.com/open-mmlab/mmengine) v0.2.0 or higher | ||
| - [MMSegmentation](https://github.com/open-mmlab/mmsegmentation) v1.0.0rc5 | ||
|
|
||
| All the commands below rely on the correct configuration of PYTHONPATH, which should point to the project's directory so that Python can locate the module files. In isic2016_task1/ root directory, run the following line to add the current directory to PYTHONPATH: | ||
|
|
||
| ```shell | ||
| export PYTHONPATH=`pwd`:$PYTHONPATH | ||
| ``` | ||
|
|
||
| ### Dataset preparing | ||
|
|
||
| - download dataset from [here](https://challenge.isic-archive.com/data/#2016) and decompression data to path 'data/'. | ||
| - run script `"python tools/prepare_dataset.py"` to split dataset and change folder structure as below. | ||
| - run script `"python ../../tools/split_seg_dataset.py"` to split dataset and generate `train.txt` and `test.txt`. If the label of official validation set and test set can't be obtained, we generate `train.txt` and `val.txt` from the training set randomly. | ||
|
|
||
| ```none | ||
| mmsegmentation | ||
| ├── mmseg | ||
| ├── projects | ||
| │ ├── medical | ||
| │ │ ├── 2d_image | ||
| │ │ │ ├── dermoscopy | ||
| │ │ │ │ ├── isic2016_task1 | ||
| │ │ │ │ │ ├── configs | ||
| │ │ │ │ │ ├── datasets | ||
| │ │ │ │ │ ├── tools | ||
| │ │ │ │ │ ├── data | ||
| │ │ │ │ │ │ ├── train.txt | ||
| │ │ │ │ │ │ ├── test.txt | ||
| │ │ │ │ │ │ ├── images | ||
| │ │ │ │ │ │ │ ├── train | ||
| │ │ │ │ | │ │ │ ├── xxx.png | ||
| │ │ │ │ | │ │ │ ├── ... | ||
| │ │ │ │ | │ │ │ └── xxx.png | ||
| │ │ │ │ │ │ │ ├── test | ||
| │ │ │ │ | │ │ │ ├── yyy.png | ||
| │ │ │ │ | │ │ │ ├── ... | ||
| │ │ │ │ | │ │ │ └── yyy.png | ||
| │ │ │ │ │ │ ├── masks | ||
| │ │ │ │ │ │ │ ├── train | ||
| │ │ │ │ | │ │ │ ├── xxx.png | ||
| │ │ │ │ | │ │ │ ├── ... | ||
| │ │ │ │ | │ │ │ └── xxx.png | ||
| │ │ │ │ │ │ │ ├── test | ||
| │ │ │ │ | │ │ │ ├── yyy.png | ||
| │ │ │ │ | │ │ │ ├── ... | ||
| │ │ │ │ | │ │ │ └── yyy.png | ||
| ``` | ||
|
|
||
| ### Training commands | ||
|
|
||
| ```shell | ||
| mim train mmseg ./configs/${CONFIG_PATH} | ||
| ``` | ||
|
|
||
| To train on multiple GPUs, e.g. 8 GPUs, run the following command: | ||
|
|
||
| ```shell | ||
| mim train mmseg ./configs/${CONFIG_PATH} --launcher pytorch --gpus 8 | ||
| ``` | ||
|
|
||
| ### Testing commands | ||
|
|
||
| ```shell | ||
| mim test mmseg ./configs/${CONFIG_PATH} --checkpoint ${CHECKPOINT_PATH} | ||
| ``` | ||
|
|
||
| <!-- List the results as usually done in other model's README. [Example](https://github.com/open-mmlab/mmsegmentation/tree/dev-1.x/configs/fcn#results-and-models) | ||
| You should claim whether this is based on the pre-trained weights, which are converted from the official release; or it's a reproduced result obtained from retraining the model in this project. --> | ||
|
|
||
| ## Results | ||
|
|
||
| ### ISIC-2016 Task1 | ||
|
|
||
| | Method | Backbone | Crop Size | lr | mIoU | mDice | config | | ||
| | :-------------: | :------: | :-------: | :----: | :--: | :---: | :---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------: | | ||
| | fcn_unet_s5-d16 | unet | 512x512 | 0.01 | - | - | [config](https://github.com/open-mmlab/mmsegmentation/tree/dev-1.x/projects/medical/2d_image/dermoscopy/isic2016_task1/configs/fcn-unet-s5-d16_unet_1xb16-0.01-20k_isic2016-task1-512x512.py) | | ||
| | fcn_unet_s5-d16 | unet | 512x512 | 0.001 | - | - | [config](https://github.com/open-mmlab/mmsegmentation/tree/dev-1.x/projects/medical/2d_image/dermoscopy/isic2016_task1/configs/fcn-unet-s5-d16_unet_1xb16-0.001-20k_isic2016-task1-512x512.py) | | ||
| | fcn_unet_s5-d16 | unet | 512x512 | 0.0001 | - | - | [config](https://github.com/open-mmlab/mmsegmentation/tree/dev-1.x/projects/medical/2d_image/dermoscopy/isic2016_task1/configs/fcn-unet-s5-d16_unet_1xb16-0.0001-20k_isic2016-task1-512x512.py) | | ||
|
|
||
| ## Checklist | ||
|
|
||
| - [x] Milestone 1: PR-ready, and acceptable to be one of the `projects/`. | ||
|
|
||
| - [x] Finish the code | ||
|
|
||
| - [x] Basic docstrings & proper citation | ||
|
|
||
| - [x] Test-time correctness | ||
|
|
||
| - [x] A full README | ||
|
|
||
| - [x] Milestone 2: Indicates a successful model implementation. | ||
|
|
||
| - [x] Training-time correctness | ||
|
|
||
| - [ ] Milestone 3: Good to be a part of our core package! | ||
|
|
||
| - [ ] Type hints and docstrings | ||
|
|
||
| - [ ] Unit tests | ||
|
|
||
| - [ ] Code polishing | ||
|
|
||
| - [ ] Metafile.yml | ||
|
|
||
| - [ ] Move your modules into the core package following the codebase's file hierarchy structure. | ||
|
|
||
| - [ ] Refactor your modules into the core package following the codebase's file hierarchy structure. |
17 changes: 17 additions & 0 deletions
17
...py/isic2016_task1/configs/fcn-unet-s5-d16_unet_1xb16-0.0001-20k_isic2016-task1-512x512.py
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,17 @@ | ||
| _base_ = [ | ||
| 'mmseg::_base_/models/fcn_unet_s5-d16.py', './isic2016-task1_512x512.py', | ||
| 'mmseg::_base_/default_runtime.py', | ||
| 'mmseg::_base_/schedules/schedule_20k.py' | ||
| ] | ||
| custom_imports = dict(imports='datasets.isic2016-task1_dataset') | ||
| img_scale = (512, 512) | ||
| data_preprocessor = dict(size=img_scale) | ||
| optimizer = dict(lr=0.0001) | ||
| optim_wrapper = dict(optimizer=optimizer) | ||
| model = dict( | ||
| data_preprocessor=data_preprocessor, | ||
| decode_head=dict(num_classes=2), | ||
| auxiliary_head=None, | ||
| test_cfg=dict(mode='whole', _delete_=True)) | ||
| vis_backends = None | ||
| visualizer = dict(vis_backends=vis_backends) |
17 changes: 17 additions & 0 deletions
17
...opy/isic2016_task1/configs/fcn-unet-s5-d16_unet_1xb16-0.001-20k_isic2016-task1-512x512.py
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,17 @@ | ||
| _base_ = [ | ||
| 'mmseg::_base_/models/fcn_unet_s5-d16.py', './isic2016-task1_512x512.py', | ||
| 'mmseg::_base_/default_runtime.py', | ||
| 'mmseg::_base_/schedules/schedule_20k.py' | ||
| ] | ||
| custom_imports = dict(imports='datasets.isic2016-task1_dataset') | ||
| img_scale = (512, 512) | ||
| data_preprocessor = dict(size=img_scale) | ||
| optimizer = dict(lr=0.001) | ||
| optim_wrapper = dict(optimizer=optimizer) | ||
| model = dict( | ||
| data_preprocessor=data_preprocessor, | ||
| decode_head=dict(num_classes=2), | ||
| auxiliary_head=None, | ||
| test_cfg=dict(mode='whole', _delete_=True)) | ||
| vis_backends = None | ||
| visualizer = dict(vis_backends=vis_backends) |
17 changes: 17 additions & 0 deletions
17
...copy/isic2016_task1/configs/fcn-unet-s5-d16_unet_1xb16-0.01-20k_isic2016-task1-512x512.py
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,17 @@ | ||
| _base_ = [ | ||
| 'mmseg::_base_/models/fcn_unet_s5-d16.py', './isic2016-task1_512x512.py', | ||
| 'mmseg::_base_/default_runtime.py', | ||
| 'mmseg::_base_/schedules/schedule_20k.py' | ||
| ] | ||
| custom_imports = dict(imports='datasets.isic2016-task1_dataset') | ||
| img_scale = (512, 512) | ||
| data_preprocessor = dict(size=img_scale) | ||
| optimizer = dict(lr=0.01) | ||
| optim_wrapper = dict(optimizer=optimizer) | ||
| model = dict( | ||
| data_preprocessor=data_preprocessor, | ||
| decode_head=dict(num_classes=2), | ||
| auxiliary_head=None, | ||
| test_cfg=dict(mode='whole', _delete_=True)) | ||
| vis_backends = None | ||
| visualizer = dict(vis_backends=vis_backends) |
42 changes: 42 additions & 0 deletions
42
projects/medical/2d_image/dermoscopy/isic2016_task1/configs/isic2016-task1_512x512.py
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,42 @@ | ||
| dataset_type = 'ISIC2017Task1' | ||
| data_root = 'data/' | ||
| img_scale = (512, 512) | ||
| train_pipeline = [ | ||
| dict(type='LoadImageFromFile'), | ||
| dict(type='LoadAnnotations'), | ||
| dict(type='Resize', scale=img_scale, keep_ratio=False), | ||
| dict(type='RandomFlip', prob=0.5), | ||
| dict(type='PhotoMetricDistortion'), | ||
| dict(type='PackSegInputs') | ||
| ] | ||
| test_pipeline = [ | ||
| dict(type='LoadImageFromFile'), | ||
| dict(type='Resize', scale=img_scale, keep_ratio=False), | ||
| dict(type='LoadAnnotations'), | ||
| dict(type='PackSegInputs') | ||
| ] | ||
| train_dataloader = dict( | ||
| batch_size=16, | ||
| num_workers=4, | ||
| persistent_workers=True, | ||
| sampler=dict(type='InfiniteSampler', shuffle=True), | ||
| dataset=dict( | ||
| type=dataset_type, | ||
| data_root=data_root, | ||
| ann_file='train.txt', | ||
| data_prefix=dict(img_path='images/', seg_map_path='masks/'), | ||
| pipeline=train_pipeline)) | ||
| val_dataloader = dict( | ||
| batch_size=1, | ||
| num_workers=4, | ||
| persistent_workers=True, | ||
| sampler=dict(type='DefaultSampler', shuffle=False), | ||
| dataset=dict( | ||
| type=dataset_type, | ||
| data_root=data_root, | ||
| ann_file='test.txt', | ||
| data_prefix=dict(img_path='images/', seg_map_path='masks/'), | ||
| pipeline=test_pipeline)) | ||
| test_dataloader = val_dataloader | ||
| val_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU', 'mDice']) | ||
| test_evaluator = dict(type='IoUMetric', iou_metrics=['mIoU', 'mDice']) |
30 changes: 30 additions & 0 deletions
30
projects/medical/2d_image/dermoscopy/isic2016_task1/datasets/isic2016-task1_dataset.py
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,30 @@ | ||
| from mmseg.datasets import BaseSegDataset | ||
| from mmseg.registry import DATASETS | ||
|
|
||
|
|
||
| @DATASETS.register_module() | ||
| class ISIC2017Task1(BaseSegDataset): | ||
| """ISIC2017Task1 dataset. | ||
| In segmentation map annotation for ISIC2017Task1, | ||
| ``reduce_zero_label`` is fixed to False. The ``img_suffix`` | ||
| is fixed to '.png' and ``seg_map_suffix`` is fixed to '.png'. | ||
| Args: | ||
| img_suffix (str): Suffix of images. Default: '.png' | ||
| seg_map_suffix (str): Suffix of segmentation maps. Default: '.png' | ||
| reduce_zero_label (bool): Whether to mark label zero as ignored. | ||
| Default to False. | ||
| """ | ||
| METAINFO = dict(classes=('normal', 'skin lesion')) | ||
|
|
||
| def __init__(self, | ||
| img_suffix='.png', | ||
| seg_map_suffix='.png', | ||
| reduce_zero_label=False, | ||
| **kwargs) -> None: | ||
| super().__init__( | ||
| img_suffix=img_suffix, | ||
| seg_map_suffix=seg_map_suffix, | ||
| reduce_zero_label=reduce_zero_label, | ||
| **kwargs) |
120 changes: 120 additions & 0 deletions
120
projects/medical/2d_image/dermoscopy/isic2016_task1/tools/prepare_dataset.py
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,120 @@ | ||
| import glob | ||
| import os | ||
| import shutil | ||
|
|
||
| import numpy as np | ||
| from PIL import Image | ||
|
|
||
|
|
||
| def check_maskid(train_imgs): | ||
| for i in train_masks: | ||
| img = Image.open(i) | ||
| print(np.unique(np.array(img))) | ||
|
|
||
|
|
||
| def reformulate_file(image_list, mask_list): | ||
| file_list = [] | ||
| for idx, (imgp, | ||
| maskp) in enumerate(zip(sorted(image_list), sorted(mask_list))): | ||
| item = {'image': imgp, 'label': maskp} | ||
| file_list.append(item) | ||
| return file_list | ||
|
|
||
|
|
||
| def check_file_exist(pair_list): | ||
| rel_path = os.getcwd() | ||
| for idx, sample in enumerate(pair_list): | ||
| image_path = sample['image'] | ||
| assert os.path.exists(os.path.join(rel_path, image_path)) | ||
| if 'label' in sample: | ||
| mask_path = sample['label'] | ||
| assert os.path.exists(os.path.join(rel_path, mask_path)) | ||
| print('all file path ok!') | ||
|
|
||
|
|
||
| def convert_maskid(mask): | ||
| # add mask id conversion | ||
| arr_mask = np.array(mask).astype(np.uint8) | ||
| arr_mask[arr_mask == 255] = 1 | ||
| return Image.fromarray(arr_mask) | ||
|
|
||
|
|
||
| def process_dataset(file_lists, part_dir_dict): | ||
| for ith, part in enumerate(file_lists): | ||
| part_dir = part_dir_dict[ith] | ||
| for sample in part: | ||
| # read image and mask | ||
| image_path = sample['image'] | ||
| if 'label' in sample: | ||
| mask_path = sample['label'] | ||
|
|
||
| basename = os.path.basename(image_path) | ||
| targetname = basename.split('.')[0] # from image name | ||
|
|
||
| # check image file | ||
| img_save_path = os.path.join(root_path, 'images', part_dir, | ||
| targetname + save_img_suffix) | ||
| if not os.path.exists(img_save_path): | ||
| if not image_path.endswith('.png'): | ||
| src = Image.open(image_path) | ||
| src.save(img_save_path) | ||
| else: | ||
| shutil.copy(image_path, img_save_path) | ||
|
|
||
| if mask_path is not None: | ||
| mask_save_path = os.path.join(root_path, 'masks', part_dir, | ||
| targetname + save_seg_map_suffix) | ||
| if not os.path.exists(mask_save_path): | ||
| # check mask file | ||
| mask = Image.open(mask_path).convert('L') | ||
| # convert mask id | ||
| mask = convert_maskid(mask) | ||
| if not mask_path.endswith('.png'): | ||
| mask.save(mask_save_path) | ||
| else: | ||
| mask.save(mask_save_path) | ||
|
|
||
| # print image num | ||
| part_dir_folder = os.path.join(root_path, 'images', part_dir) | ||
| print( | ||
| f'{part_dir} has {len(os.listdir(part_dir_folder))} images completed!' # noqa | ||
| ) | ||
|
|
||
|
|
||
| if __name__ == '__main__': | ||
|
|
||
| root_path = 'data/' # original file | ||
| img_suffix = '.jpg' | ||
| seg_map_suffix = '.png' | ||
| save_img_suffix = '.png' | ||
| save_seg_map_suffix = '.png' | ||
|
|
||
| train_imgs = glob.glob('data/ISBI2016_ISIC_Part1_Training_Data/*' # noqa | ||
| + img_suffix) | ||
| train_masks = glob.glob( | ||
| 'data/ISBI2016_ISIC_Part1_Training_GroundTruth/*' # noqa | ||
| + seg_map_suffix) | ||
|
|
||
| test_imgs = glob.glob('data/ISBI2016_ISIC_Part1_Test_Data/*' + img_suffix) | ||
| test_masks = glob.glob( | ||
| 'data/ISBI2016_ISIC_Part1_Test_GroundTruth/*' # noqa | ||
| + seg_map_suffix) | ||
|
|
||
| assert len(train_imgs) == len(train_masks) | ||
| assert len(test_imgs) == len(test_masks) | ||
|
|
||
| print(f'training images: {len(train_imgs)}, test images: {len(test_imgs)}') | ||
|
|
||
| os.system('mkdir -p ' + root_path + 'images/train/') | ||
| os.system('mkdir -p ' + root_path + 'images/test/') | ||
| os.system('mkdir -p ' + root_path + 'masks/train/') | ||
| os.system('mkdir -p ' + root_path + 'masks/test/') | ||
|
|
||
| train_pair_list = reformulate_file(train_imgs, train_masks) | ||
| test_pair_list = reformulate_file(test_imgs, test_masks) | ||
|
|
||
| check_file_exist(train_pair_list) | ||
| check_file_exist(test_pair_list) | ||
|
|
||
| part_dir_dict = {0: 'train/', 1: 'test/'} | ||
| process_dataset([train_pair_list, test_pair_list], part_dir_dict) |