

Add sleuth to the classpath of a Spring Boot application (see below for Maven and Gradle examples), and you will see the correlation data being collected in logs, as long as you are logging requests.
Example HTTP handler:
@RestController
public class DemoController {
private static Logger log = LoggerFactory.getLogger(DemoController.class);
@RequestMapping("/")
public String home() {
log.info("Handling home");
...
return "Hello World";
}
}You will see the calls to home() traced in the logs and in Zipkin, if that is configured.
|
Note
|
instead of logging the request in the handler explicitly, you
could set logging.level.org.springframework.web.servlet.DispatcherServlet=DEBUG
|
|
Note
|
Set spring.application.name=bar (for instance) to see the
service name as well as the trace and span ids.
|
Spring Cloud Sleuth implements a distributed tracing solution for Spring Cloud.
Spring Cloud Sleuth borrows Dapper’s terminology.
Span: The basic unit of work. For example, sending an RPC is a new span, as is sending a response to an RPC. Span’s are identified by a unique 64-bit ID for the span and another 64-bit ID for the trace the span is a part of. Spans also have other data, such as descriptions, timestamped events, key-value annotations (tags), the ID of the span that caused them, and process ID’s (normally IP address).
Spans are started and stopped, and they keep track of their timing information. Once you create a span, you must stop it at some point in the future.
|
Tip
|
The initial span that starts a trace is called a root span. The value of span id
of that span is equal to trace id.
|
Trace: A set of spans forming a tree-like structure. For example, if you are running a distributed big-data store, a trace might be formed by a put request.
Annotation: is used to record existence of an event in time. With Brave instrumentation we no longer need to set special events for Zipkin to understand who the client and server are and where the request started and where it has ended. For learning purposes however we will mark these events to highlight what kind of an action took place.
-
cs - Client Sent - The client has made a request. This annotation depicts the start of the span.
-
sr - Server Received - The server side got the request and will start processing it. If one subtracts the cs timestamp from this timestamp one will receive the network latency.
-
ss - Server Sent - Annotated upon completion of request processing (when the response got sent back to the client). If one subtracts the sr timestamp from this timestamp one will receive the time needed by the server side to process the request.
-
cr - Client Received - Signifies the end of the span. The client has successfully received the response from the server side. If one subtracts the cs timestamp from this timestamp one will receive the whole time needed by the client to receive the response from the server.
Visualization of what Span and Trace will look in a system together with the Zipkin annotations:

Each color of a note signifies a span (7 spans - from A to G). If you have such information in the note:
Trace Id = X
Span Id = D
Client SentThat means that the current span has Trace-Id set to X, Span-Id set to D. Also, the Client Sent event took place.
This is how the visualization of the parent / child relationship of spans would look like:

In the following sections the example from the image above will be taken into consideration.
Altogether there are 7 spans . If you go to traces in Zipkin you will see this number in the second trace:

However if you pick a particular trace then you will see 4 spans:

|
Note
|
When picking a particular trace you will see merged spans. That means that if there were 2 spans sent to Zipkin with Server Received and Server Sent / Client Received and Client Sent annotations then they will presented as a single span. |
Why is there a difference between the 7 and 4 spans in this case?
-
2 spans come from
http:/startspan. It has the Server Received (SR) and Server Sent (SS) annotations. -
2 spans come from the RPC call from
service1toservice2to thehttp:/fooendpoint. The Client Sent (CS) and Client Received (CR) events took place onservice1side. Server Received (SR) and Server Sent (SS) events took place on theservice2side. Physically there are 2 spans but they form 1 logical span related to an RPC call. -
2 spans come from the RPC call from
service2toservice3to thehttp:/barendpoint. The Client Sent (CS) and Client Received (CR) events took place onservice2side. Server Received (SR) and Server Sent (SS) events took place on theservice3side. Physically there are 2 spans but they form 1 logical span related to an RPC call. -
2 spans come from the RPC call from
service2toservice4to thehttp:/bazendpoint. The Client Sent (CS) and Client Received (CR) events took place onservice2side. Server Received (SR) and Server Sent (SS) events took place on theservice4side. Physically there are 2 spans but they form 1 logical span related to an RPC call.
So if we count the physical spans we have 1 from http:/start, 2 from service1 calling service2, 2 form service2
calling service3 and 2 from service2 calling service4. Altogether 7 spans.
Logically we see the information of Total Spans: 4 because we have 1 span related to the incoming request
to service1 and 3 spans related to RPC calls.
Zipkin allows you to visualize errors in your trace. When an exception was thrown and wasn’t caught then we’re setting proper tags on the span which Zipkin can properly colorize. You could see in the list of traces one trace that was in red color. That’s because there was an exception thrown.
If you click that trace then you’ll see a similar picture
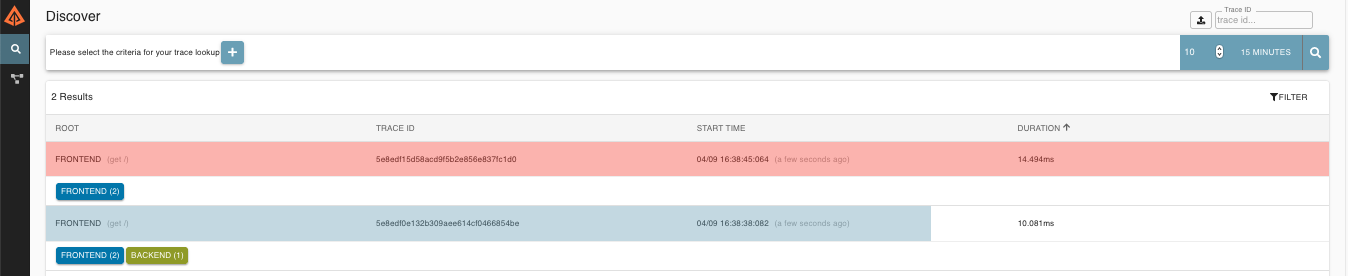
Then if you click on one of the spans you’ll see the following
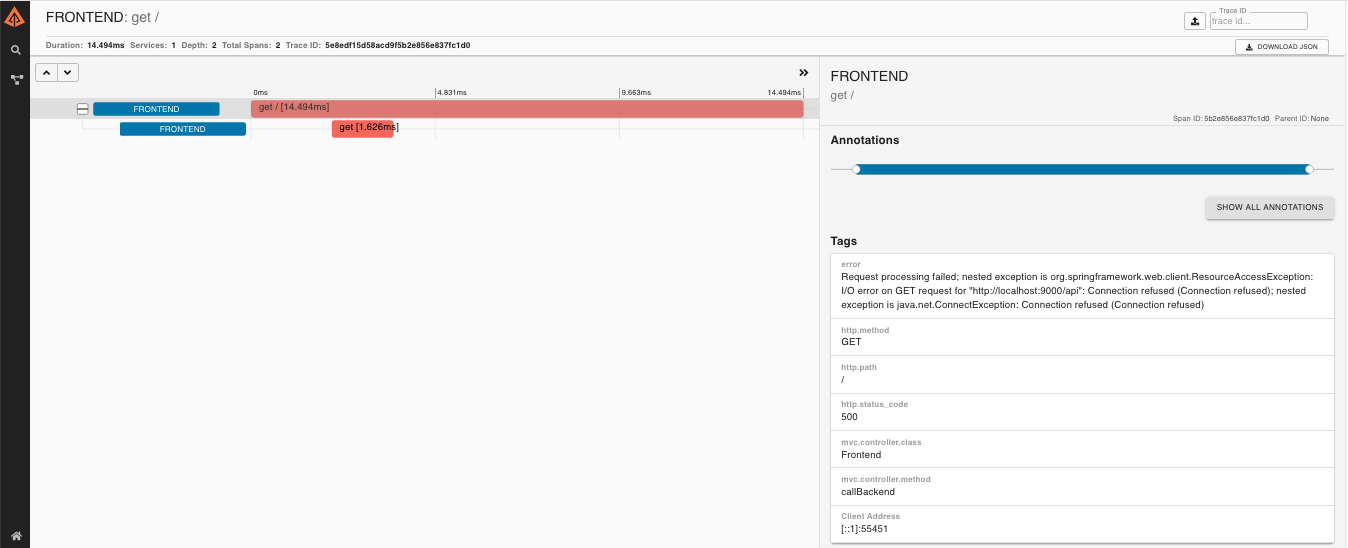
As you can see you can easily see the reason for an error and the whole stacktrace related to it.
Starting with version 2.0.0, Spring Cloud Sleuth uses
Brave as the tracing library. That means
that Sleuth no longer takes care of storing the context but it delegates
that work to Brave.
Due to the fact that Sleuth had different naming / tagging
conventions than Brave, we’ve decided to follow the Brave’s
conventions from now on. However, if you want to use the legacy
Sleuth approaches, it’s enough to set the spring.sleuth.http.legacy.enabled property
to true.

The dependency graph in Zipkin would look like this:

When grepping the logs of those four applications by trace id equal to e.g. 2485ec27856c56f4 one would get the following:
service1.log:2016-02-26 11:15:47.561 INFO [service1,2485ec27856c56f4,2485ec27856c56f4,true] 68058 --- [nio-8081-exec-1] i.s.c.sleuth.docs.service1.Application : Hello from service1. Calling service2
service2.log:2016-02-26 11:15:47.710 INFO [service2,2485ec27856c56f4,9aa10ee6fbde75fa,true] 68059 --- [nio-8082-exec-1] i.s.c.sleuth.docs.service2.Application : Hello from service2. Calling service3 and then service4
service3.log:2016-02-26 11:15:47.895 INFO [service3,2485ec27856c56f4,1210be13194bfe5,true] 68060 --- [nio-8083-exec-1] i.s.c.sleuth.docs.service3.Application : Hello from service3
service2.log:2016-02-26 11:15:47.924 INFO [service2,2485ec27856c56f4,9aa10ee6fbde75fa,true] 68059 --- [nio-8082-exec-1] i.s.c.sleuth.docs.service2.Application : Got response from service3 [Hello from service3]
service4.log:2016-02-26 11:15:48.134 INFO [service4,2485ec27856c56f4,1b1845262ffba49d,true] 68061 --- [nio-8084-exec-1] i.s.c.sleuth.docs.service4.Application : Hello from service4
service2.log:2016-02-26 11:15:48.156 INFO [service2,2485ec27856c56f4,9aa10ee6fbde75fa,true] 68059 --- [nio-8082-exec-1] i.s.c.sleuth.docs.service2.Application : Got response from service4 [Hello from service4]
service1.log:2016-02-26 11:15:48.182 INFO [service1,2485ec27856c56f4,2485ec27856c56f4,true] 68058 --- [nio-8081-exec-1] i.s.c.sleuth.docs.service1.Application : Got response from service2 [Hello from service2, response from service3 [Hello from service3] and from service4 [Hello from service4]]If you’re using a log aggregating tool like Kibana, Splunk etc. you can order the events that took place. An example of Kibana would look like this:
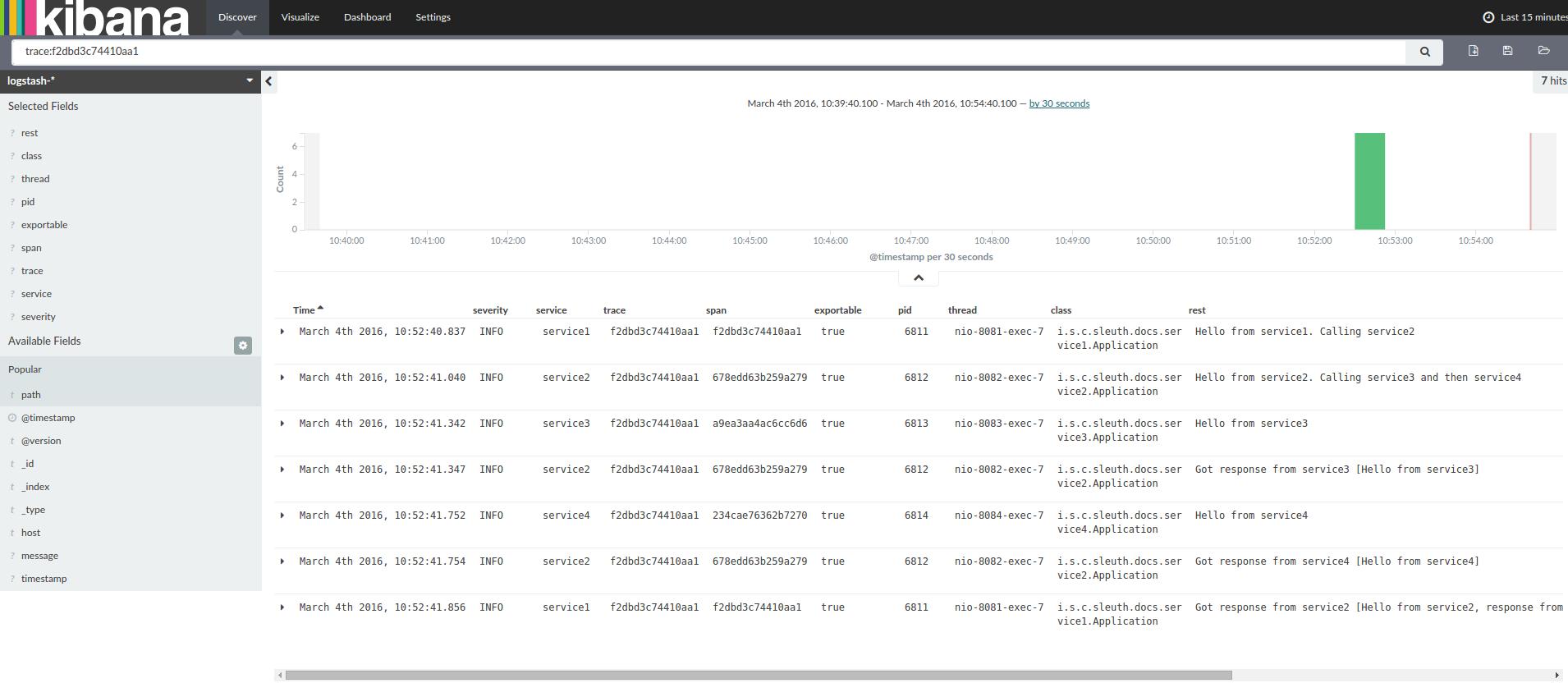
If you want to use Logstash here is the Grok pattern for Logstash:
filter {
# pattern matching logback pattern
grok {
match => { "message" => "%{TIMESTAMP_ISO8601:timestamp}\s+%{LOGLEVEL:severity}\s+\[%{DATA:service},%{DATA:trace},%{DATA:span},%{DATA:exportable}\]\s+%{DATA:pid}\s+---\s+\[%{DATA:thread}\]\s+%{DATA:class}\s+:\s+%{GREEDYDATA:rest}" }
}
}|
Note
|
If you want to use Grok together with the logs from Cloud Foundry you have to use this pattern: |
filter {
# pattern matching logback pattern
grok {
match => { "message" => "(?m)OUT\s+%{TIMESTAMP_ISO8601:timestamp}\s+%{LOGLEVEL:severity}\s+\[%{DATA:service},%{DATA:trace},%{DATA:span},%{DATA:exportable}\]\s+%{DATA:pid}\s+---\s+\[%{DATA:thread}\]\s+%{DATA:class}\s+:\s+%{GREEDYDATA:rest}" }
}
}Often you do not want to store your logs in a text file but in a JSON file that Logstash can immediately pick. To do that you have to do the following (for readability
we’re passing the dependencies in the groupId:artifactId:version notation.
Dependencies setup
-
Ensure that Logback is on the classpath (
ch.qos.logback:logback-core) -
Add Logstash Logback encode - example for version
4.6:net.logstash.logback:logstash-logback-encoder:4.6
Logback setup
Below you can find an example of a Logback configuration (file named logback-spring.xml) that:
-
logs information from the application in a JSON format to a
build/${spring.application.name}.jsonfile -
has commented out two additional appenders - console and standard log file
-
has the same logging pattern as the one presented in the previous section
<?xml version="1.0" encoding="UTF-8"?>
<configuration>
<include resource="org/springframework/boot/logging/logback/defaults.xml"/>
<springProperty scope="context" name="springAppName" source="spring.application.name"/>
<!-- Example for logging into the build folder of your project -->
<property name="LOG_FILE" value="${BUILD_FOLDER:-build}/${springAppName}"/>
<!-- You can override this to have a custom pattern -->
<property name="CONSOLE_LOG_PATTERN"
value="%clr(%d{yyyy-MM-dd HH:mm:ss.SSS}){faint} %clr(${LOG_LEVEL_PATTERN:-%5p}) %clr(${PID:- }){magenta} %clr(---){faint} %clr([%15.15t]){faint} %clr(%-40.40logger{39}){cyan} %clr(:){faint} %m%n${LOG_EXCEPTION_CONVERSION_WORD:-%wEx}"/>
<!-- Appender to log to console -->
<appender name="console" class="ch.qos.logback.core.ConsoleAppender">
<filter class="ch.qos.logback.classic.filter.ThresholdFilter">
<!-- Minimum logging level to be presented in the console logs-->
<level>DEBUG</level>
</filter>
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>utf8</charset>
</encoder>
</appender>
<!-- Appender to log to file -->
<appender name="flatfile" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_FILE}</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_FILE}.%d{yyyy-MM-dd}.gz</fileNamePattern>
<maxHistory>7</maxHistory>
</rollingPolicy>
<encoder>
<pattern>${CONSOLE_LOG_PATTERN}</pattern>
<charset>utf8</charset>
</encoder>
</appender>
<!-- Appender to log to file in a JSON format -->
<appender name="logstash" class="ch.qos.logback.core.rolling.RollingFileAppender">
<file>${LOG_FILE}.json</file>
<rollingPolicy class="ch.qos.logback.core.rolling.TimeBasedRollingPolicy">
<fileNamePattern>${LOG_FILE}.json.%d{yyyy-MM-dd}.gz</fileNamePattern>
<maxHistory>7</maxHistory>
</rollingPolicy>
<encoder class="net.logstash.logback.encoder.LoggingEventCompositeJsonEncoder">
<providers>
<timestamp>
<timeZone>UTC</timeZone>
</timestamp>
<pattern>
<pattern>
{
"severity": "%level",
"service": "${springAppName:-}",
"trace": "%X{X-B3-TraceId:-}",
"span": "%X{X-B3-SpanId:-}",
"parent": "%X{X-B3-ParentSpanId:-}",
"exportable": "%X{X-Span-Export:-}",
"pid": "${PID:-}",
"thread": "%thread",
"class": "%logger{40}",
"rest": "%message"
}
</pattern>
</pattern>
</providers>
</encoder>
</appender>
<root level="INFO">
<appender-ref ref="console"/>
<!-- uncomment this to have also JSON logs -->
<!--<appender-ref ref="logstash"/>-->
<!--<appender-ref ref="flatfile"/>-->
</root>
</configuration>|
Note
|
If you’re using a custom logback-spring.xml then you have to pass the spring.application.name in
bootstrap instead of application property file. Otherwise your custom logback file won’t read the property properly.
|
The span context is the state that must get propagated to any child Spans across process boundaries. Part of the Span Context is the Baggage. The trace and span IDs are a required part of the span context. Baggage is an optional part.
Baggage is a set of key:value pairs stored in the span context. Baggage travels together with the trace
and is attached to every span. Spring Cloud Sleuth will understand that a header is baggage related if the HTTP
header is prefixed with baggage- and for messaging it starts with baggage_.
|
Important
|
There’s currently no limitation of the count or size of baggage items. However, keep in mind that too many can decrease system throughput or increase RPC latency. In extreme cases, it could crash the app due to exceeding transport-level message or header capacity. |
Example of setting baggage on a span:
Span initialSpan = this.tracer.nextSpan().name("span").start();
try (Tracer.SpanInScope ws = this.tracer.withSpanInScope(initialSpan)) {
ExtraFieldPropagation.set("foo", "bar");
ExtraFieldPropagation.set("UPPER_CASE", "someValue");
}Baggage travels with the trace (i.e. every child span contains the baggage of its parent). Zipkin has no knowledge of baggage and will not even receive that information.
Tags are attached to a specific span - they are presented for that particular span only. However you can search by tag to find the trace, where there exists a span having the searched tag value.
If you want to be able to lookup a span based on baggage, you should add corresponding entry as a tag in the root span.
|
Important
|
Remember that the span needs to be in scope! |
initialSpan.tag("foo",
ExtraFieldPropagation.get(initialSpan.context(), "foo"));
initialSpan.tag("UPPER_CASE",
ExtraFieldPropagation.get(initialSpan.context(), "UPPER_CASE"));|
Important
|
To ensure that your application name is properly displayed in Zipkin
set the spring.application.name property in bootstrap.yml.
|
If you want to profit only from Spring Cloud Sleuth without the Zipkin integration just add
the spring-cloud-starter-sleuth module to your project.
<dependencyManagement> (1)
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${release.train.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependency> (2)
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>-
In order not to pick versions by yourself it’s much better if you add the dependency management via the Spring BOM
-
Add the dependency to
spring-cloud-starter-sleuth
dependencyManagement { (1)
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:${releaseTrainVersion}"
}
}
dependencies { (2)
compile "org.springframework.cloud:spring-cloud-starter-sleuth"
}-
In order not to pick versions by yourself it’s much better if you add the dependency management via the Spring BOM
-
Add the dependency to
spring-cloud-starter-sleuth
If you want both Sleuth and Zipkin just add the spring-cloud-starter-zipkin dependency.
<dependencyManagement> (1)
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${release.train.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependency> (2)
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>-
In order not to pick versions by yourself it’s much better if you add the dependency management via the Spring BOM
-
Add the dependency to
spring-cloud-starter-zipkin
dependencyManagement { (1)
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:${releaseTrainVersion}"
}
}
dependencies { (2)
compile "org.springframework.cloud:spring-cloud-starter-zipkin"
}-
In order not to pick versions by yourself it’s much better if you add the dependency management via the Spring BOM
-
Add the dependency to
spring-cloud-starter-zipkin
If you want to use RabbitMQ or Kafka instead of http, add the spring-rabbit or spring-kafka
dependencies. The default destination name is zipkin.
Note: spring-cloud-sleuth-stream is deprecated and incompatible with these destinations
If you want Sleuth over RabbitMQ add the spring-cloud-starter-zipkin and spring-rabbit
dependencies.
<dependencyManagement> (1)
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>${release.train.version}</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
<dependency> (2)
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
<dependency> (3)
<groupId>org.springframework.amqp</groupId>
<artifactId>spring-rabbit</artifactId>
</dependency>-
In order not to pick versions by yourself it’s much better if you add the dependency management via the Spring BOM
-
Add the dependency to
spring-cloud-starter-zipkin- that way all dependent dependencies will be downloaded -
To automatically configure rabbit, simply add the spring-rabbit dependency
dependencyManagement { (1)
imports {
mavenBom "org.springframework.cloud:spring-cloud-dependencies:${releaseTrainVersion}"
}
}
dependencies {
compile "org.springframework.cloud:spring-cloud-starter-zipkin" (2)
compile "org.springframework.amqp:spring-rabbit" (3)
}-
In order not to pick versions by yourself it’s much better if you add the dependency management via the Spring BOM
-
Add the dependency to
spring-cloud-starter-zipkin- that way all dependent dependencies will be downloaded -
To automatically configure rabbit, simply add the spring-rabbit dependency
-
Adds trace and span ids to the Slf4J MDC, so you can extract all the logs from a given trace or span in a log aggregator. Example logs:
2016-02-02 15:30:57.902 INFO [bar,6bfd228dc00d216b,6bfd228dc00d216b,false] 23030 --- [nio-8081-exec-3] ... 2016-02-02 15:30:58.372 ERROR [bar,6bfd228dc00d216b,6bfd228dc00d216b,false] 23030 --- [nio-8081-exec-3] ... 2016-02-02 15:31:01.936 INFO [bar,46ab0d418373cbc9,46ab0d418373cbc9,false] 23030 --- [nio-8081-exec-4] ...
notice the
[appname,traceId,spanId,exportable]entries from the MDC:-
spanId - the id of a specific operation that took place
-
appname - the name of the application that logged the span
-
traceId - the id of the latency graph that contains the span
-
exportable - whether the log should be exported to Zipkin or not. When would you like the span not to be exportable? In the case in which you want to wrap some operation in a Span and have it written to the logs only.
-
-
Provides an abstraction over common distributed tracing data models: traces, spans (forming a DAG), annotations, key-value annotations. Loosely based on HTrace, but Zipkin (Dapper) compatible.
-
Sleuth records timing information to aid in latency analysis. Using sleuth, you can pinpoint causes of latency in your applications. Sleuth is written to not log too much, and to not cause your production application to crash.
-
propagates structural data about your call-graph in-band, and the rest out-of-band.
-
includes opinionated instrumentation of layers such as HTTP
-
includes sampling policy to manage volume
-
can report to a Zipkin system for query and visualization
-
-
Instruments common ingress and egress points from Spring applications (servlet filter, async endpoints, rest template, scheduled actions, message channels, zuul filters, feign client).
-
Sleuth includes default logic to join a trace across http or messaging boundaries. For example, http propagation works via Zipkin-compatible request headers. This propagation logic is defined and customized via
SpanInjectorandSpanExtractorimplementations. -
Sleuth gives you the possibility to propagate context (also known as baggage) between processes. That means that if you set on a Span a baggage element then it will be sent downstream either via HTTP or messaging to other processes.
-
Provides a way to create / continue spans and add tags and logs via annotations.
-
If
spring-cloud-sleuth-zipkinis on the classpath then the app will generate and collect Zipkin-compatible traces. By default it sends them via HTTP to a Zipkin server on localhost (port 9411). Configure the location of the service usingspring.zipkin.baseUrl.-
If you depend on
spring-rabbitorspring-kafkayour app will send traces to a broker instead of http. -
Note:
spring-cloud-sleuth-streamis deprecated and should no longer be used.
-
-
Spring Cloud Sleuth is OpenTracing compatible
|
Important
|
If using Zipkin, configure the percentage of spans exported using spring.sleuth.sampler.percentage
(default 0.1, i.e. 10%). Otherwise you might think that Sleuth is not working cause it’s omitting some spans.
|
|
Note
|
the SLF4J MDC is always set and logback users will immediately see the trace and span ids in logs per the example
above. Other logging systems have to configure their own formatter to get the same result. The default is
logging.pattern.level set to %5p [${spring.zipkin.service.name:${spring.application.name:-}},%X{X-B3-TraceId:-},%X{X-B3-SpanId:-},%X{X-Span-Export:-}]
(this is a Spring Boot feature for logback users).
This means that if you’re not using SLF4J this pattern WILL NOT be automatically applied.
|
To build the source you will need to install JDK 1.7.
Spring Cloud uses Maven for most build-related activities, and you should be able to get off the ground quite quickly by cloning the project you are interested in and typing
$ ./mvnw install
|
Note
|
You can also install Maven (>=3.3.3) yourself and run the mvn command
in place of ./mvnw in the examples below. If you do that you also
might need to add -P spring if your local Maven settings do not
contain repository declarations for spring pre-release artifacts.
|
|
Note
|
Be aware that you might need to increase the amount of memory
available to Maven by setting a MAVEN_OPTS environment variable with
a value like -Xmx512m -XX:MaxPermSize=128m. We try to cover this in
the .mvn configuration, so if you find you have to do it to make a
build succeed, please raise a ticket to get the settings added to
source control.
|
For hints on how to build the project look in .travis.yml if there
is one. There should be a "script" and maybe "install" command. Also
look at the "services" section to see if any services need to be
running locally (e.g. mongo or rabbit). Ignore the git-related bits
that you might find in "before_install" since they’re related to setting git
credentials and you already have those.
The projects that require middleware generally include a
docker-compose.yml, so consider using
Docker Compose to run the middeware servers
in Docker containers. See the README in the
scripts demo
repository for specific instructions about the common cases of mongo,
rabbit and redis.
|
Note
|
If all else fails, build with the command from .travis.yml (usually
./mvnw install).
|
The spring-cloud-build module has a "docs" profile, and if you switch
that on it will try to build asciidoc sources from
src/main/asciidoc. As part of that process it will look for a
README.adoc and process it by loading all the includes, but not
parsing or rendering it, just copying it to ${main.basedir}
(defaults to ${basedir}, i.e. the root of the project). If there are
any changes in the README it will then show up after a Maven build as
a modified file in the correct place. Just commit it and push the change.
If you don’t have an IDE preference we would recommend that you use Spring Tools Suite or Eclipse when working with the code. We use the m2eclipse eclipse plugin for maven support. Other IDEs and tools should also work without issue as long as they use Maven 3.3.3 or better.
We recommend the m2eclipse eclipse plugin when working with eclipse. If you don’t already have m2eclipse installed it is available from the "eclipse marketplace".
|
Note
|
Older versions of m2e do not support Maven 3.3, so once the
projects are imported into Eclipse you will also need to tell
m2eclipse to use the right profile for the projects. If you
see many different errors related to the POMs in the projects, check
that you have an up to date installation. If you can’t upgrade m2e,
add the "spring" profile to your settings.xml. Alternatively you can
copy the repository settings from the "spring" profile of the parent
pom into your settings.xml.
|
If you prefer not to use m2eclipse you can generate eclipse project metadata using the following command:
$ ./mvnw eclipse:eclipse
The generated eclipse projects can be imported by selecting import existing projects
from the file menu.
|
Important
|
There are 2 different versions of language level used in Spring Cloud Sleuth. Java 1.7 is used for main sources and
Java 1.8 is used for tests. When importing your project to an IDE please activate the ide Maven profile to turn on
Java 1.8 for both main and test sources. Of course remember that you MUST NOT use Java 1.8 features in the main sources. If you do
so your app will break during the Maven build.
|
Spring Cloud is released under the non-restrictive Apache 2.0 license, and follows a very standard Github development process, using Github tracker for issues and merging pull requests into master. If you want to contribute even something trivial please do not hesitate, but follow the guidelines below.
Before we accept a non-trivial patch or pull request we will need you to sign the Contributor License Agreement. Signing the contributor’s agreement does not grant anyone commit rights to the main repository, but it does mean that we can accept your contributions, and you will get an author credit if we do. Active contributors might be asked to join the core team, and given the ability to merge pull requests.
This project adheres to the Contributor Covenant code of conduct. By participating, you are expected to uphold this code. Please report unacceptable behavior to [email protected].
None of these is essential for a pull request, but they will all help. They can also be added after the original pull request but before a merge.
-
Use the Spring Framework code format conventions. If you use Eclipse you can import formatter settings using the
eclipse-code-formatter.xmlfile from the Spring Cloud Build project. If using IntelliJ, you can use the Eclipse Code Formatter Plugin to import the same file. -
Make sure all new
.javafiles to have a simple Javadoc class comment with at least an@authortag identifying you, and preferably at least a paragraph on what the class is for. -
Add the ASF license header comment to all new
.javafiles (copy from existing files in the project) -
Add yourself as an
@authorto the .java files that you modify substantially (more than cosmetic changes). -
Add some Javadocs and, if you change the namespace, some XSD doc elements.
-
A few unit tests would help a lot as well — someone has to do it.
-
If no-one else is using your branch, please rebase it against the current master (or other target branch in the main project).
-
When writing a commit message please follow these conventions, if you are fixing an existing issue please add
Fixes gh-XXXXat the end of the commit message (where XXXX is the issue number).