This repository has been archived by the owner on Sep 10, 2024. It is now read-only.
-
Notifications
You must be signed in to change notification settings - Fork 24
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
Add readme for spinning up notebooks
- Loading branch information
1 parent
42cac8a
commit 91c1ffd
Showing
1 changed file
with
69 additions
and
0 deletions.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,69 @@ | ||
| # Spin up Jupyter Notebooks with Trace DSL | ||
|
|
||
| Jupyter notebooks provide a simple user interface for experimenting with data. There are two main use cases that we want to accomplish with the notebooks: | ||
|
|
||
| - an interface for data scientists to experiment with tracing data | ||
| - on-demand incident investigation | ||
|
|
||
| The second point is the reason why we have developed Trace DSL based on graph query language Gremlin to simplify filtering and feature extraction of tracing data. Because such analysis might not be feasible in the user interface where thousands of traces or set of traces with hundreds or thousands of spans are to be analysed. Hence a Jaeger user would be able to spin up a Jupyter notebook on demand with the Trace DSL and write a query and analysis. | ||
|
|
||
| ## Jupyter notebook example with Jaeger | ||
|
|
||
| Now, let's see how we can deploy Jupyter notebook with Jaeger trace DSL and write a simple query against the Jaeger server. | ||
|
|
||
| For this, first we need to deploy Jaeger UI, HotROD - a demo application and Jupyter notebook with Trace DSL. | ||
|
|
||
| 1. For Jaeger UI: | ||
|
|
||
| ``` bash | ||
| docker run --rm -it -p 16686:16686 --name=jaeger jaegertracing/all-in-one:1.17 | ||
| ``` | ||
| This will open up the Jager UI at [http://localhost:16686](http://localhost:16686/) | ||
|
|
||
| 2. For HotROD demo application, run | ||
| ``` bash | ||
| docker run --rm -it -p 8080:8080 --link=jaeger -e JAEGER_ENDPOINT=http://jaeger:14268/api/traces jaegertracing/example-hotrod:1.17 | ||
| ``` | ||
| This will start the application at [http://localhost:8080](http://localhost:8080/) | ||
|
|
||
| 3. Lastly, for spinning up the notebook that are hosted in this [repository](https://github.com/jaegertracing/jaeger-analytics-java) | ||
|
|
||
|
|
||
| ``` bash | ||
| docker run --rm -it -p 8888:8888 -p 4041:4040 -p 9001:9001 --link=jaeger -e JUPYTER_ENABLE_LAB=yes quay.io/jaegertracing/jaeger-analytics-java:latest | ||
| ``` | ||
|
|
||
| *Note : Add `-v ${PWD}:/home/jovyan/work` to Jupyter notebook if you want to open the notebooks from your current directory.* | ||
|
|
||
| After succesfully running the docker script, you will be able to see a URL in you terminal with unique token. Paste that URL in your browser to start the jupyter notebook. | ||
|
|
||
| ## Analysis | ||
|
|
||
| For the analysis we have to generate some data, so in the HotROD UI click on the blue boxes to order a car that generates nice traces. To verify that the trace reached Jaeger open Jaeger UI and search for traces from the `frontend` service. | ||
| The trace should look like this: | ||
|
|
||
| 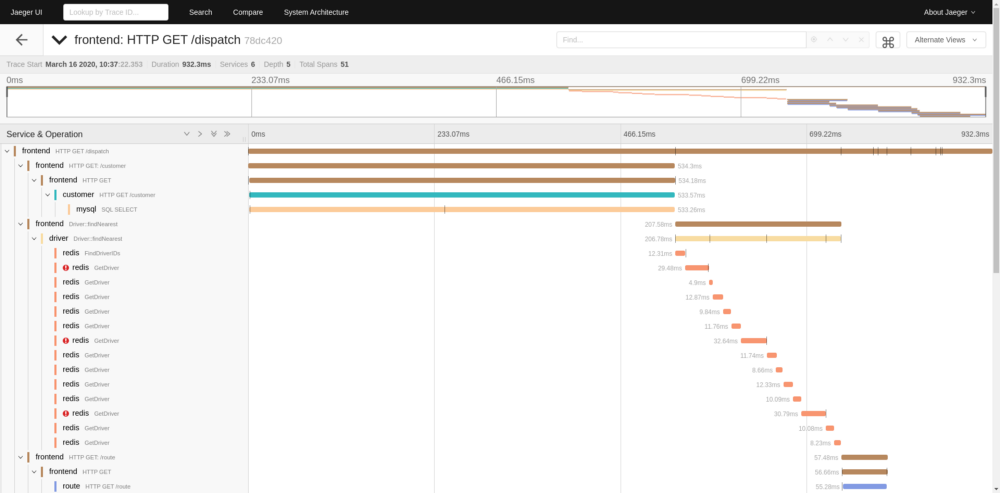 | ||
|
|
||
| Once we know that the data is stored in Jaeger we can move to Jupyter notebook and load the trace there. Jaeger notebooks are stored in thejupyter directory. This directory can either be opened from the project root directory or from work in case the notebooks from host filesystem are injected into the docker container. | ||
|
|
||
| Before running the analysis we have to load dependencies into the notebook’s classpath. Just click on the dependencies cell to make it active and then on the play icon in the top navigation menu. | ||
|
|
||
| 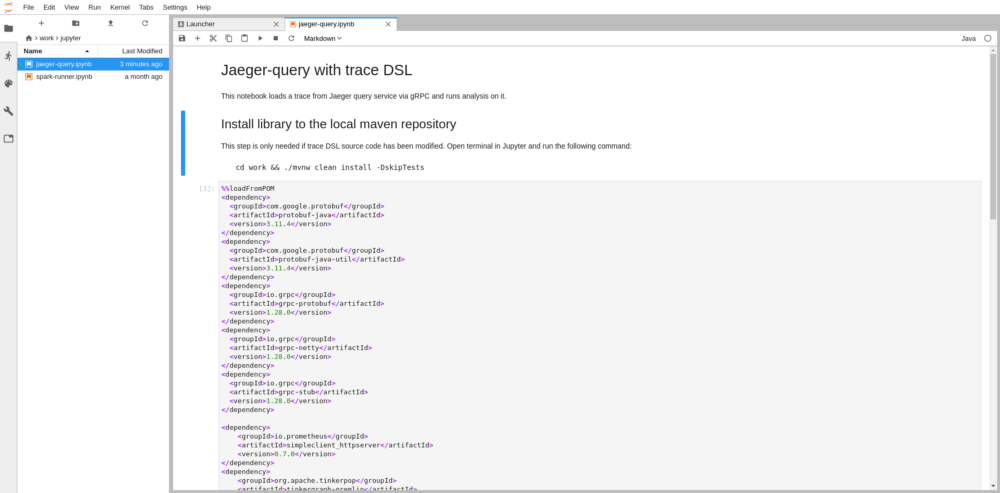 | ||
|
|
||
| Before running the code we have to update the variable `traceIdStr` to point into one of the traces we have generated earlier in the HotROD app. | ||
|
|
||
| 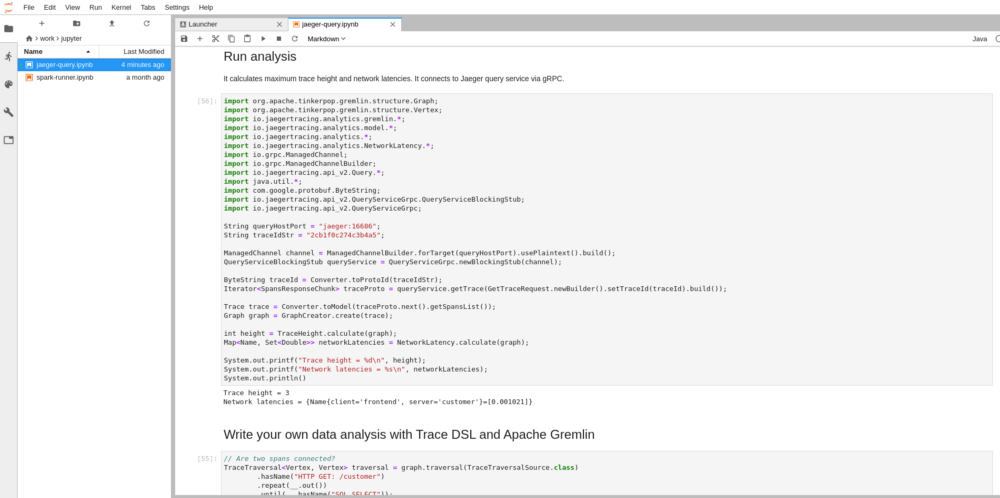 | ||
|
|
||
| The results are written below the code cell. In this case the trace has the height 3 and there is one calculated network latency between frontend and server service of 0.00102 ms . The latency is small because all services are run as part of the same process and there is no real network overhead. | ||
|
|
||
| The last code cell shows the direct use of Trace DSL with Apache Gremlin. Gremlin is a graph traversal language and class TraceTraversalSource.class it extends and adds methods for trace filtering and feature extraction. For instance, it adds a method like `hasName(String name)` to filter spans by operation name. In our example the query verifies whether two spans with given operation names are directly or indirectly connected, or in other words one is a descendant of the other. | ||
|
|
||
| 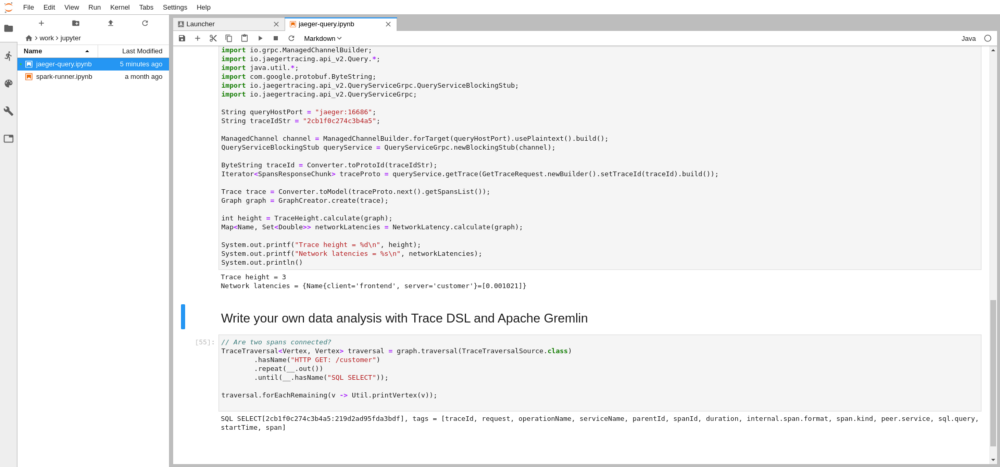 | ||
|
|
||
| This feature provides a powerful interface to write a custom query and hypothesis analysis against traces retrieved from the Jaeger server. The example can easily be extended to collect a stream of traces from Kafka and experiment on the live data. | ||
|
|
||
| ## References | ||
|
|
||
| 1. [Data analytics with Jaeger blog post](https://medium.com/jaegertracing/data-analytics-with-jaeger-aka-traces-tell-us-more-973669e6f848) | ||
| 2. [Apache Gremlin documentation](http://tinkerpop.apache.org/docs/current/reference/) | ||
| 3. [Jaeger HotROD example application demo](https://medium.com/opentracing/take-opentracing-for-a-hotrod-ride-f6e3141f7941) |