rbh3_cfg_ref
General structure
The configuration file consists of several blocks. They can contain key/value pairs (separated by semi-colons), sub-blocks, Boolean expressions or set definitions (see 'set definitions' below).
In some cases, blocks have an identifier.
BLOCK_1 bloc_id {
Key = value;
Key = value(opt1, opt2);
Key = value;
SUBBLOCK1 {
key = value;
}
}
BLOCK_2 {
(key > value)
and
(key == value or key != value)
}
CLASS_DEF {
Set1 union Set2
}
Type of values
A value can be:
- A string delimited by single or double quotes ( ' or " ).
- An environment variable, starting with $ (e.g. $ROOT_PATH).
- A Boolean constant. Both of the following values are accepted and the case is not significant: TRUE, FALSE, YES, NO, 0, 1, ENABLED, DISABLED.
- A number: decimal representation, or decimal representation with suffix: k, M, G, T.
- A duration, i.e. a numerical value followed by one of those suffixes: 'w' for weeks, 'd' for days, 'h' for hours, 'min' for minutes, 's' for seconds. E.g.: 1s ; 1min ; 3h ; …NB: if you do not specify a suffix, the duration is interpreted as seconds. E.g.: 60 will be interpreted at 60s, i.e.1 min.
- A size, i.e. a numerical value followed by one of those suffixes: PB for petabytes, TB for terabytes, GB for gigabytes, MB for megabytes, KB for kilobytes. No suffix is needed for bytes.
- A percentage: float value terminated by '%'. E.g.: 87.5%
Some blocks of configuration file are expected to be Boolean expressions on file attributes:
- AND, OR and NOT can be used in Boolean expressions.
- Parenthesis can be used for including sub-expressions.
- Conditions on attributes are specified with the following format:<attribute> <comparator> <value>.
- Allowed comparators are '==', '<>' or '!=', '>', '>=', '<', '<='.
-
tree: entry is in the given filesystem tree. Shell-like wildcards are allowed. Example: tree == "/tmp/subdir/*/dir1" matches entry "/tmp/subdir/foo/dir1/dir2/foo" because "/tmp/subdir/foo/dir1/dir2/foo" is in the "/tmp/subdir/foo/dir1" tree, that matches "/tmp/subdir/*/dir1" expression.
The special wildcard "**" matches any count of directory levels:
E.g: tree == "**/.trash" matches any part of a filesystem under a ".trash" entry.
-
path: entry exactly matches the path. Shell-like wildcards are allowed. E.g: path == "/tmp/*/foo*" matches entry "/tmp/subdir/foo123".
The special wildcard "**" matches any count of directory levels:
E.g: path == "**/.trash/**/file" matches any entry called "file" located somewhere under a ".trash" directory (at any depth).
- name: entry name matches the given regexp. E.g: name == "*.log" matches entry "/tmp/dir/foo/abc.log".
- type: entry has the given type (directory, file, symlink, chr, blk, fifo or sock). E.g: type == "symlink".
- owner: entry has the given owner (owner name expected). E.g: owner == "root".
- group: entry is owned by the given group (group name expected).
- size: entry has the specified size. Value can be suffixed with KB, MB, GB… E.g: size >= 100MB matches file whose size equals 100x1024x1024 bytes or more.
- last_access: condition based on the last access time to a file (for reading or writing). This is the difference between current time and max(atime, mtime, ctime). Value can be suffixed by 'sec', 'min', 'hour', 'day', 'week'… E.g: last_access < 1h matches files that have been read or written within the last hour.
- last_mod: condition based on the last modification time to a file. This is the difference between current time and max(mtime, ctime). E.g: last_mod > 1d matches files that have not been modified for more than a day.
- creation: condition based on file creation time. With scanning mode, this value is an estimation based on the time when robinhood sees a file for the first time and ctime. E.g.: creation > 1h matches files created more than 1 hour ago.
- [lustre only] ost_index: condition on OSTs where a file is stored. A file can be striped on several OSTs. In this case:
ost_index == ''N'' is true if at least one part of the file is stored in OST index N.
ost_index != ''N'' is true if no part of the file is stored in OST index N.
- [lustre only] ost_pool: condition about the OST pool name where the file was created. Wildcarded expressions are allowed.E.g. ost_pool == "pool*".
-
xattr.xxx: test the value of a user-defined extended attribute of the file.
- xattr values are interpreted as text string
- regular expressions can be used to match xattr values. E.g: xattr.user.foo == "abc.[1-5].*" matches file having xattr user.foo = "abc.2.xyz"
- if an extended attribute is not set for a file, it matches empty string. Eg. xattr.user.foo == "" is satisfied if xattr 'user.foo' is not defined.
- dircount (for directories only): the directory has the specified number of entries (except '.' and '..'). E.g: dircount > 10000 matches directories with more that 10 thousand child entries.
- Policy-specific attributes. Depending on the status managers used in policies, policy-specific attributes can be used in policy rules, e.g "lhsm.status", "lhsm.last_archive", ... See status manager plugins documentation for more details.
ignore {
( name == "*.log" and size < 15GB )
or ( owner == "root" and last_access < 2d )
or not tree == "/fs/dir"
}
Set definitions
In the case of FileClass definitions, you can define FileClasses as the union or intersection of other FileClasses previously defined. This can be done using "union", "inter" and "not" keyworks. Such expressions can be encapsulated between parenthesis.
Example:
FileClass my_set_union {
definition { ( Class1 union Class2 ) inter ( not Class3 ) }
}
Comments
The '#' and '//' signs indicate the beginning of a comment (except if there are in a quoted string). The comment ends at the end of the line.
E.g.:
x = 32 ; # a comment can also be placed after a significant line
Includes
A configuration file can be included from another file using the '%include' directive. Both relative and absolute paths can be used.
E.g.:
'''%include''' "subdir/common.conf"
Configuration blocks
The main blocks in a configuration file are:
- General (mandatory): main parameters.
- Log: log and alert parameters (log files, log level…).
- Fileclass: definition of a file classe.
- define_policy policyname: define a custom policy.
- policy_rules: specify application rules for a policy.
- policy_parameters: specify parameters for a policy.
- policy_trigger: specify condition to trigger policy runs.
- ListManager (mandatory): database access configuration.
- FS_Scan: options about scanning the filesystem.
- db_update_params: parameters about file class periodic matching, and entry information update interval.
- ChangeLog: parameters related to Lustre 2.x changelogs.
- EntryProcessor: configuration of entry processing pipeline (for FS scan, changelog ingestion...).
Template file
To easily create a configuration file, you can generate a documented template using the --template option of robinhood, and edit this file to set the values for your system:
robinhood --template=<template file>
Default configuration values
To know the default values of configuration parameters use the --defaults option:
robinhood --defaults
General parameters are set in a configuration block whose name is 'General'.
The following parameters can be specified in this block:
- fs_path (string, mandatory): the path of the file system to be managed. This must be an absolute path. This parameter can be overridden by "--fs-path" parameter on command line.E.g.: fs_path = "/tmp_fs";
- fs_type (string, mandatory): the type of the filesystem to be managed (as displayed by mount). This is mainly used for checking if the filesystem is mounted. This parameter can be overridden by "--fs-type" parameter on command line.E.g.: fs_type = "lustre";
-
fs_key: this indicates the filesystem property used as unique and persistent file system identifier. Possible values are: 'fsname', 'devid' or 'fsid' ('fsid' is NOT recommended as it may change at each mount).
- stay_in_fs (Boolean): if this parameter is TRUE, robinhood checks that the entries it handles are in the same device as fs_path, which prevents from traversing mount points.E.g.: stay_in_fs = TRUE;
- check_mounted (Boolean): if this parameter is TRUE, robinhood checks that the filesystem of fs_path is mounted.E.g.: check_mounted = TRUE;
- last_access_only_atime(boolean):
- uid_gid_as_numbers(boolean):
- direct_mds_stat(boolean):
The parameters described in this section can be specified in the 'Log' block. They control logging, reporting and alerts.
Logging parameters
-
debug_level (string): verbosity level of logs. This parameter can be overridden by"--log-level" parameter on command line.Allowed values are :
- FULL: highest level of verbosity. Trace everything.
- DEBUG: trace information for debugging.
- VERB: high level of traces (but usable in production).
- EVENT: standard production log level.
- MAJOR: only trace major events.
- CRIT: only trace critical events.
- log_file (string): file where logs are written. This parameter can be overridden by"--log-file" parameter on command line.E.g.: log_file = "/var/logs/robinhood/robinhood.log";
- report_file (string): file where purge and rmdir operations are logged.E.g.: report_file = "/var/logs/robinhood/purge_report.log";
- Make sure the log directory exists.
- robinhood is compliant with log rotation (if its log file is renamed, it will automatically open a new file).
- The following special values can be used as log files:
- 'stdout': log to standard output
- 'stderr': log to standard error
- 'syslog': log using syslog
- For syslog, you can select the syslog facility using the 'syslog_facility' parameter.E.g:log_file = syslog ;syslog_facility = local1.info ;
In the previous versions of robinhood, log lines always had the following format:<date> <time> <process name>@<hostname>[pid/thrd]: <module> | <log msg>
Now the default log header is shorter:<date> <time> [pid/thrd] <module> | <log msg>
but you can still add additional info in the log using new configuration parameters:
- log_procname (boolean): display the process name in the log header (default : 'no').
- log_hostname (boolean): display the host name in the log header (default : 'no').
-
log_module (boolean): display the module name in the log header (default : 'yes').
Two methods can be used for raising alerts: sending a mail, writing to a file, or both.
This is set by the following parameters:
- alert_file (string): if this parameter is set, alerts are written to the specified file.E.g.: alert_file = "/var/logs/robinhood/alerts.log";
- alert_mail (string): if this parameter is set, mail alerts are sent to the specified recipient.E.g.: alert_mail = "admin@localdomain";
- alert_show_attrs (Boolean): If true, details entry attributes in alerts.
-
batch_alert_max (integer): this controls alert batching (sending 1 alert summary instead of 1 per entry):
- If the value is 0, there is no limit in batching alerts. 1 summary is send after each scan.
- If the value is 1, alerts are not batched.
- If the value is N > 1, a summary is sent every N alerts.
You may need to apply different purge policies depending on file properties. To do this, you can define file classes.
A file class is defined by a 'FileClass' block. All file class definitions must be grouped in the 'Filesets' block of the configuration file.
Each file class has an identifier (that you can use for addressing it in policies) and a definition (a condition for entries to be in this file class).FileClasses can be defined as the union or the intersection of other FileClasses, using 'inter' and 'union' keywords in fileclass definition.
File classes definition overview:
Filesets {
FileClass my_class_1 {
Definition {
tree == "/fs/dir_A"
and
owner == root
}
}
FileClass my_class_2 {
...
}
FileClass my_inter_class {
Definition { my_class_1 inter my_class_3 }
}
...
}
Important note: if you modify fileclass definitions or target fileclasses of policies, you need to reset fileclass information in Robinhood database.
To do so, run the following command:
rbh-config reset_classes
In general, files are purged in the order of their last access time (LRU list). You can however specify conditions to allow/avoid entries to be purged, depending on their file class, and file properties.
To define purge policies, you can specify:
- Sets of entries that must never be purged (ignored).
- Purge policies to be applied to file classes.
- A default purge policy for entries that don't match any file class.
- 'Ignore' sub-blocks: Boolean expressions to "white-list" filesystem entries depending on their properties.E.g.: Ignore { size == 0 or type == "symlink" }
- 'Ignore_fileclass': "white-list" all entries of a fileclass (see section 3.5 about defining File classes).E.g.: Ignore_FileClass = my_class_1;
- 'Policy' sub-blocks: specify conditions for purging entries of file classes.A policy has a custom name, one or several target file classes, and a condition for purging files. E.g:
Policy purge_classes_2and3
{
target_fileclass = class_2;
target_fileclass = class_3;
condition { Last_access > 1h }
}
- A default policy that applies to files that don't match any previous file class or 'ignore' directive. It is a special 'Policy' block whose name is 'default' and with no target_fileclass. E.g:
Policy default {
condition { last_access > 30min }
}
As a summary, the 'purge_policies' block will look like this:
purge_policies {
# don't purge symlinks and entries owned by root
Ignore { owner == "root" or type == symlink }
# don't purge files of classes 'class_xxx' and 'class_yyy'
Ignore_FileClass = class_xxx ;
Ignore_FileClass = class_yyy ;
# purge policy for files of 'my_class1' and 'my_class2'
policy my_purge_policy1 {
target_fileclass = my_class1;
target_fileclass = my_class2;
condition { last_access > 1h and last_mod > 2h }
}
...
# purge policy for other files
policy default {
condition { last_access > 10min }
}
}
Note: the target fileclasses are matched in the order they appear in the purge_policies block, so make sure to specify the more restrictive classes first.Thus, in the following example, the second policy can't never be matched, because A already matches all entries in A_inter_B:
Filesets {
Fileclass A { ... }
Fileclass B { ... }
Fileclass A_inter_B { definition { A inter B } }
}
purge_policies {
policy purge_1 {
target_fileclass = A; # all entries of fileclass A
...
}
policy purge_2 {
target_fileclass = A_inter_B; # never matched!!!
...
}
}
Triggers describe conditions for starting/stopping purges. They are defined by 'purge_trigger' blocks. Each trigger consists of:
- The type of condition (on global filesystem usage, on OST usage, on volume used by a user or a group…).
- A purge start condition.
- A purge target condition.
- An interval for checking start condition.
- Notification options.
Type of condition
The type of condition is specified by "trigger_on" parameter.Possible values are:
- global_usage: purge start/stop condition is based on the spaced used in the whole filesystem (based on df return). All entries in filesystem are considered for such a purge.
- OST_usage: purge start/stop condition is based on the space used on each OST (based on lfs df). Only files stored in an OST are considered for such a purge.
-
user_usage[(user1, user2…)]: purge start/stop condition is based on the space used by a user (kind of quota). Only files that are owned by a user over the limit are considered for such a purge. If it is used with no arguments, all users will be affected by this policy.
-
group_usage[(grp1, grp2…)]: purge start/stop condition is based on the space used by a group (kind of quota). Only files that are owned by a group over the limit are considered for purge. If it is used with no arguments, all groups will be affected by this policy.
- periodic: purge runs at scheduled interval, with no condition on filesystem usage.
This is mandatory for all types of conditions.
A purge start condition can be specified by two ways: percentage or volume.
- high_threshold_pct (percentage): specifies a percentage of space used over which a purge is launched.
- high_threshold_vol (size): specifies a volume of space used over which a purge is launched. The value for this parameter can be suffixed by KB, MB, GB, TB…
- high_threshold_cnt (count): condition based on the number of inodes in the filesystem. It can be used for global_usage, user_usage and group_usage triggers. The value can be suffixed by K, M, …
Stop condition
This is mandatory for all types of conditions.
A purge stop condition can also be specified by two ways: percentage or volume.
- low_threshold_pct: specifies a percentage of space used under which a purge stops.
- low_threshold_vol: specifies a volume of space used under which a purge stops. The value for this parameter can be suffixed by KB, MB, TB… (the value is interpreted as bytes if no suffix is specified).
- low_threshold_cnt (count): condition based on the number of inodes in the filesystem. It can be used for global_usage, user_usage and group_usage triggers. The value can be suffixed by K, M, …
Runtime interval
The time interval for checking a condition is set by parameter "check_interval". The value for this parameter can be suffixed by 'sec', 'min', 'hour', 'day', 'week', 'year'… (the value is interpreted as seconds if no suffix is specified).
Raising an alert when high threshold is reached
Optionally, an alert can be raised each time the high threshold is reached. This can be done by setting the "alert_high" parameter (Boolean) in the trigger:
alert_high = TRUE;
Don't raise an alert when low threshold cannot be reached
By default, robinhood raises an alert if it can't purge enough data to reach the low threshold.
You can disable these alerts by adding this in a trigger definition:
alert_low = FALSE ;
Examples
Check 'df' every 5 minutes, start a purge if space used > 85% of filesystem and stop purging when space used reaches 84.5%:
Purge_Trigger {
trigger_on = global_usage ;
high_threshold_pct = 85% ;
low_threshold_pct = 84.5% ;
check_interval = 5min ;
}
Check OST usage every 5 minutes, start a purge of files on an OST if it space used is over 90% and stop purging when space used on the OST falls to 85%:
Purge_Trigger {
trigger_on = OST_usage ;
high_threshold_pct = 90% ;
low_threshold_pct = 85% ;
check_interval = 5min ;
}
Daily check the space used by each user of a given list. If one of them uses more than 1TB, its files are purged until it uses less than 800GB. Also send an alert in this case.
Purge_Trigger {
trigger_on = user_usage(foo, charlie, roger, project*) ;
high_threshold_vol = 1TB ;
low_threshold_vol = 800GB ;
check_interval = 1day ;
alert_high = TRUE ;
}
Check that user inode usage is less than 100k entries (and send a notification in this case):
Purge_Trigger {
trigger_on = user_usage ;
high_threshold_cnt = 100k ;
low_threshold_cnt = 100k ;
check_interval = 1day ;
alert_high = TRUE ;
}
Apply purge policies twice a day (whatever the filesystem usage):
Purge_Trigger {
trigger_on = periodic;
check_interval = 12h;
}
Note: check triggers conditions without purging
If robinhood is started with the '--check-thresholds' option instead of '--purge', it will only check for trigger conditions and eventually send notifications, without purging data.
Purge parameters are specified in a 'purge_parameters' block.
The following options can be set:
- nb_threads_purge (integer): this determines the number of purge operations that can be performed in parallel. E.g.: nb_threads_purge = 8 ;
-
post_purge_df_latency (duration): immediately after purging data, df and ost df may return a wrong value, especially if freeing disk space is asynchronous. So, it is necessary to wait for a while before issuing a new df or ost df command after a purge. This duration is set by this parameter. E.g.:
post_purge_df_latency = 1min ; - purge_queue_size (integer): this advanced parameter is for leveraging purge thread load.
- db_result_size_max (integer): this impacts memory usage of MySQL server and Robinhood daemon. The higher it is, the more memory they will use, but less DB requests will be needed.
- recheck_ignored_classes (Boolean): by default, robinhood doesn't rematch entries that matched an ignored class once for a policy (by default, recheck_ignored_classes = no). If you change policy rules or fileclass definitions, it is recommended to enable this parameter (recheck_ignored_classes = yes) to check if previously ignored entries are now eligible for the policy.
- sort (Boolean): by default, entries are purged by last access time (oldest first). This can make the purge scheduling slower as it requires to sort candidate entries by last access. This behavior can be disabled by setting sort = no in purge_parameters.
Directory removal is driven by the 'rmdir_policy' section in the configuration file:
- age_rm_empty_dirs (duration): indicates the time after which an empty directory is removed. If set to 0, empty directory removal is disabled.
- You can specify one or several 'ignore' condition for directories you never want to be removed.
- 'recursive_rmdir' sub-blocks indicates that the matching directories must be removed recursively. /!\In this case, the whole directories content is removed without checking policies on their content (whitelist rules…).
rmdir_policy {
# remove empty directories after 15 days
age_rm_empty_dirs = 15d;
# recursively remove ".trash" directories after 15 days
recursive_rmdir {
name == ".trash" and last_mod > 15d
}
# whitelist directories matching the following condition
ignore {
depth < 2
or
owner == 'foo'
or
tree == /fs/subdir/A
}
}
Directory removal parameters are specified in the 'rmdir_parameters' block.
The following options can be set:
- runtime_interval (duration): interval for performing empty directory removal.
- nb_threads_rmdir (integer): this determines the number of 'rmdir' operations that can be performed in parallel. E.g.: nb_threads_rmdir = 4;
- rmdir_op_timeout (duration): this specifies the timeout for 'rmdir' operations. If a thread is stuck in a filesystem operation during this time, it is cancelled. E.g.: rmdir_op_timeout = 15min;
- rmdir_queue_size (integer): this advanced parameter is for leveraging rmdir thread load.
By default, Robinhood matches fileclasses for an entry each time it updates its attributes. Alternatively you can match fileclasses only if it has not been updated for a given time.
The fileclass matching interval is set using the 'fileclass_update' parameter in the new 'db_update_policy' section:
db_update_policy {
fileclass_update = periodic( 1h );
}
Possible values are:
- never: match file class once, and never again
- always: always re-match file class when applying policies (this is the old behavior)
- periodic(<period>): periodically re-match fileclasses
Warning: these are advanced parameters. Changing them may affect robinhood working and cause unexpected results. It is recommended to ask robinhood-support before changing them.
This is similar to fileclass periodic matching, but it is for updating file metadata and path in the database when processing Lustre changelogs.
Indeed, if robinhood receives a lot of events for a given entry, it can be very loud to update entry information when processing each event.
You can specifies the way entry path and entry metadata is updated in the database using 'md_update' and 'path_update' parameters in the new 'db_update_policy' section:
db_update_policy {
md_update = on_event_periodic(1sec,1min);
path_update = on_event;
}
Possible values for those parameters are:
- never: retrieve it once, then never update the information
- always: always update the information when receiving an event for the entry
- periodic(<period>): update the information only if it was not updated for a while
- on_event: update the information every time the event is related to it (eg. update entry path when the event is a 'rename' on the entry).
- on_event_periodic(<interval_min>,<interval_max>): this is the smarter one
The 'ListManager' block is the configuration for accessing the database.
ListManager parameters:
-
commit_behavior: this is the method for committing information to database.The following values are allowed:
- transaction: group operations in transactions (best consistency, recommended).
- autocommit: more efficient with some DB engines, but database inconsistencies may appear.
-
periodic(<nbr_transactions>): operations are packed in large transactions before they are committed. 'Commit' is done evry n transactions. This method is more efficient for in-file databases like SQLite. This causes no database inconsistency, but more operations are lost in case of a crash.
-
connect_retry_interval_min, connect_retry_interval_max (durations): 'connect_retry_interval_min' is the time (in seconds) to wait before re-establishing a lost connection to database. If reconnection fails, this time is doubled at each retry, until 'connect_retry_interval_max'.
connect_retry_interval_max = 30;
Accounting parameters (in ListManager):
-
user_acct, group_acct (Booleans): these parameters enable or disable optimized reports for user and group statistics.By default these parameters are enabled. If you disable them (or one of them), report generation will be slower, but it will make database operation faster during filesystem scans. For instance, if you only need reports by user, disable group_acct to optimize scan speed.
group_acct = off ;
See section 10.3 for more details.
MySQL specific configuration is set in a 'MySQL' sub-block, with the following parameters:
- server: machine where MySQL server is running. Both server name and IP address can be specified. E.g.: server = "mydbhost.localnetwork.net";
- db (string, mandatory): name of the database. E.g.: db = "robinhood_db";
- user (string): name of the database user. E.g.: user = "robinhood";
- password or password_file (string, mandatory): there are two methods for specifying the password for connecting to the database, depending of the security level you want. You can directly write it in the configuration file, by setting the 'password' parameter. You can also write the password in a distinct file (with more restrictive rights) and give the path to this file by setting 'password_file' parameter. This makes it possible to have different access rights for config file and password file. E.g.: password_file = "/etc/robinhood/.dbpass";
- innodb (Boolean): this parameter is deprecated since 2.5.4. It is replaced by the 'engine' parameter (see below).
- engine(string): by default, robinhood uses InnoDB as MySQL engine. Set this parameter to use another mysql engine (e.g. engine = myisam) Note: This parameter is only used when Robinhood creates its tables the first time you start it. If tables are already created, you need to convert them using such SQL statements: ALTER TABLE t1 ENGINE=xxxx; ...
Parameters for scanning the filesystem are set in the 'FS_Scan' block.
It can contain the following parameters:
- scan_interval (duration): specifies a fix frequency for scanning the filesystem (daemon mode).
-
min_scan_interval, max_scan_interval (durations): it is possible to adapt the scan frequency depending on the current filesystem usage. Indeed, it is not necessary to scan the filesystem frequently when it is empty (because no purge is needed). When the filesystem is full, robinhood will need a fresh list for purging files, so it is better to scan more frequently. For this, specify the interval between scans using:
- min_scan_interval: the frequency for scanning when filesystem is full;
-
max_scan_interval: the frequency for scanning when filesystem is empty
min + (100% - current usage)*(max-min)
Note : those parameters are not compatible with simple scan_interval.
- nb_threads_scan (integer): number of threads used for scanning the filesystem in parallel.
- scan_retry_delay (duration): if a scan fails, this is the delay before starting another.
- scan_op_timeout (duration): this specifies the timeout for readdir/getattr operations. If filesystem operations are blocked more than this time, there are cancelled.It is recommended to enable 'exit_on_timeout' option in that case.
- exit_on_timeout (Boolean): robinhood exits if filesystem operations are blocked for a long time (specified by 'scan_op_timeout').
- spooler_check_interval (duration): interval for testing FS scans, deadlines and hangs.
- nb_prealloc_tasks (integer): number of pre-allocated task structures (advanced parameter).
-
completion_command (string): external completion command to be called when robinhood terminate a filesystem scan. The full path for the command must be specified. Command arguments can contain special values:
- {cfg} for the config file
-
{fspath} for the path of the filesystem managed by robinhood
-
Ignore block (Boolean expression): robinhood will skip entries and directories that match the given expression. Several ignore blocks can be defined in FS_Scan.
FS_Scan {
Ignore {
# ignore ".snapshot" directories (don't scan them)
type == directory
and
name == ".snapshot"
}
Ignore {
# ignore a whole part of the filesystem
tree == "/mnt/lustre/dont_scan_me"
}
...
}
With Lustre 2.x, FS scan are no longer required to update robinhood's database.Reading Lustre's changelog is much more efficient, because this does not load the filesystem as much as a full namespace scan. However, an initial scan is still required to initially populate robinhood DB.
Accessing the chngelog is driven by the 'ChangeLog' block of configuration. It contains one 'MDT' block for each MDT, with the following information:
- mdt_name (string): name of the MDT to read ChangeLog from (basically "MDT0000").
- reader_id (string): log reader identifier, returned by 'lctl changelog_register' (see section 2.6: "Enabling Lustre Changelogs").
The polling interval control the frequency for reading changelog records from the MDTs: polling_interval = 1s;
You can also control the frequency of acknowledging chengelog records to Lustre (this reduces the number of filesystem calls), by specifying batch_ack_count. Zero indicates that changelog records are acknowledged once they have all been read and processed.
E.g: clear changelog every 500 records
batch_ack_count = 500 ;
Robinhood can log every changelog record it gets from Lustre. This can be useful for debugging, or to analyze filesystem access patterns. To enable this, set the following parameter: dump_file = "/path/to/dump_file";
A basic "ChangeLog" block looks like this:
ChangeLog {
MDT {
mdt_name = "MDT0000";
reader_id = "cl1";
}
# With DNE, define 1 block per MDT.
# Here is a 2nd MDT:
MDT {
mdt_name = "MDT0001";
reader_id = "cl1";
}
}
To speed up changelog processing, robinhood retains changelog records in memory a short time, to aggregate similar/redundant Changelog records on the same entry before updating its database (e.g. both MTIME and CLOSE events mean the file mtime and size may have changed and must be updated).You can configure this batching using the following parameters in the 'Changelog' block:
- queue_max_size (integer): the maximum number of retained records. Default is 1000.
- queue_max_age (duration): the maximum time a record is retained. Default is 5s.
- queue_check_interval (duration): the period for checking records age (related to queue_max_age parameter). Default is 1s.
For handling several Lustre MDTs (with DNE), there are 2 possible configurations:
- You can run Changelog readers for all MDTs as a single Robinhood process. In this case, robinhood will have 1 changelog reader thread per MDT in the same Robinhood process. To do so, simply run Robinhood as usual (with no option, or with the --readlog option).
- You can run 1 changelog reader process per MDT, possibly distributed on different hosts. To do so, give the MDT index as an option to --readlog:
robinhood --readlog=0
on host2, to read changelogs from the second MDT (should be MDT0001):
robinhood --readlog=1
and so on…
In some past Lustre versions, there were a couple of lacks or defects in Changelog records. If your MDS runs an old version of Lustre, you can specify whether your MDS has the patches for the following bugs: LU-543 and LU-1331. This can be specified using the following parameters in the 'Changelog' block:
- mds_has_lu543 (boolean): enable if the MDS has the fix for LU-543. Disable if it has the bug.
-
mds_has_lu1331 (boolean): enable if the MDS has the fix for LU-1331. Disable if it has the bug.
When scanning a filesystem or reading changelogs, robinhood process incoming information using a pool of worker threads. The processing is based on a pipeline model, with 1 stage for each kind of operation (FS operation, DB operation ...).
The behavior of this module is controlled by the 'EntryProcessor' block.
You have the choice between 2 strategies to maximize robinhood processing speed:
- multi-threading: perform multiple DB operations in parallel as independent transactions.
- batching: batch database operations (insert, update...) into a single transaction, which minimize the need for IOPS on the database backend. Batches are not executed in parallel.
If accounting is disabled (user_acct = no, and group_acct = no), the 2 strategies can be used together, thus resulting in higher DB ingest rates (x3-x4).
So it is recommended to disable accounting for large ingest operations (initial filesystem scan, dequeuing accumulated changelogs...).
The following benchmarks evaluated the DB performance for each strategy.
The following benchmark ran on a simple test-bed using a basic SATA disk as DB storage for innodb.
Database performance benchmark over ext3/SATA:
In this configuration, batching looks more efficient than multi-threading whatever the thread count, so it has been made the defaut behavior for robinhood 2.5.
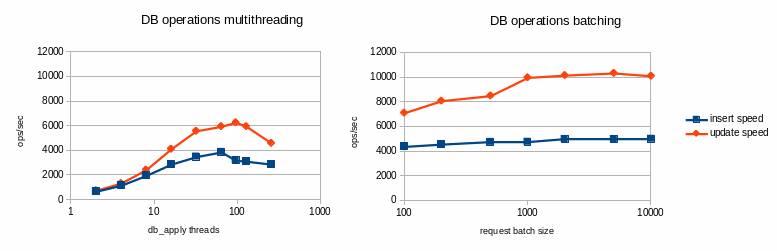
You can control batches size defining this parameter in the EntryProcessor configuration block (see section 3):
-
max_batch_size(positive integer): by default, the entry processor tries to batch similar database operations to speed them. This can be controlled by the max_batch_size parameter. The default max batch size is 1000.
The following benchmark ran on a fast device as DB storage for innodb (e.g. SSD drive).
Database performance benchmark over SSD:
In this configuration, multi-threading gives a better throughput with an optimal value of 24 pipeline threads in this case.
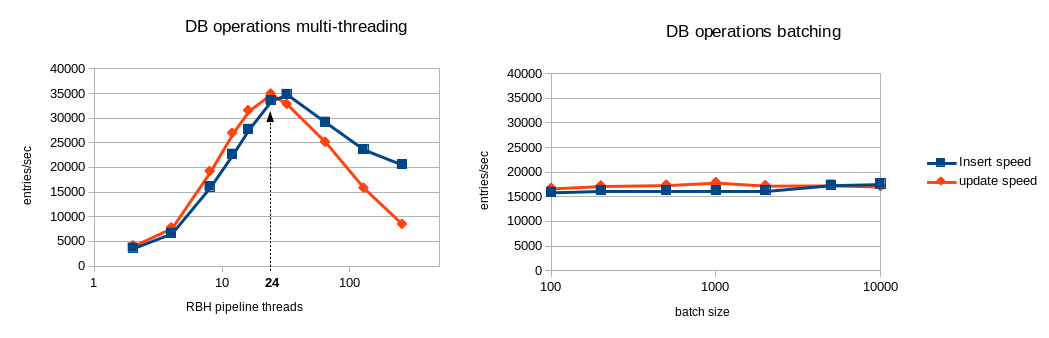
If your DB storage backend is efficient enough (high IOPS) it may be better to use the multi-threading strategy. To switch from batching strategy to multi-threading, set max_batch_size = 1. This will automatically disable batching and enables multi-threading for DB operations. Then you can tune the nb_threads parameter (in EntryProcessor configuration block) to get the optimal performance for your system:
- nb_threads (integer): total number of threads for performing pipeline tasks. Default is 16.
- STAGE_GET_FID_threads_max (integer): when scanning a filesystem, this indicates the maximum number of threads that can perform a llapi_path2fid operation simultaneously.
- STAGE_GET_INFO_DB_threads_max (integer): this limits the number of threads that simultaneously check if an entry already exists in database.
- STAGE_GET_INFO_FS_threads_max (integer): this limits the number of threads that simultaneously retrieve information from filesystem (getstripe…).
- STAGE_REPORTING_threads_max (integer): this limits the number of threads that simultaneously check and raise alerts about filesystem entries.
- STAGE_PRE_APPLY_threads_max (integer): this step is only filtering entries before the DB_APPLY step. No reason to limit it.
- STAGE_DB_APPLY_threads_max (integer): this limits the number of threads that simultaneously insert/upate entries in the database.
STAGE_DB_APPLY_threads_max = 4;
Other parameters:
-
max_pending_operations (integer): this parameter limits the number of pending operations in the pipeline, so this prevents from using too much memory. When the number of queued entries reaches this value, the scanning process is slowed-down to keep the pending operation count below this value.
One of the tasks of the Entry Processor is to check alert rules and raise alerts. For defining an alert, simply write an 'Alert' sub-block with a Boolean expression that describes the condition for raising an alert (see section 3.1 for more details about writing Boolean expressions on file attributes).
Alerts can be named, to easily identify/distinguish them in alert summaries.
E.g.: raise an alert if a directory contains more that 10 thousand entries:
Alert '''Large_flat_directory''' {
type == directory
and dircount > 10000
and last_mod < 2h
}
Another example: raise an alert if a file is larger that 100GB (except for user 'foo'):
Alert'''Big_File''' {
type == file
and size > 100GB
and owner != 'foo'
and last_mod < 2h
}
Tip: alert rules are matched at every scan. If you don't want to be alerted about a given file at each scan, it is advised to specify a condition on last_mod, so you will only be alerted for recently modified entries.
FileClass matching
By default, entry fileclass are matched immediately when entries are discovered (basically at scan time). This make it possible for the reporting command to display the fileclass information.
If the filesystem is overloaded, this can be disabled using the 'match_classes' parameter in the 'EntryProcessor' block. In this case, entry fileclasses will only be matched when applying policies. match_classes = FALSE;
Detecting "fake" mtime
You may have robinhood policies based on file modification time. If users change their file modification times using 'touch' command, 'utime' call, or copying files using 'rsync' or 'cp -p', it may result in unexpected policy decisions (like purging recently modified files because the user set a mtime in the past).
To avoid such situation, enable the 'detect_fake_mtime' parameter in the 'EntryProcessor' block: detect_fake_mtime = TRUE;
Note: robinhood traces the fake mtime it detects with 'debug' trace level.