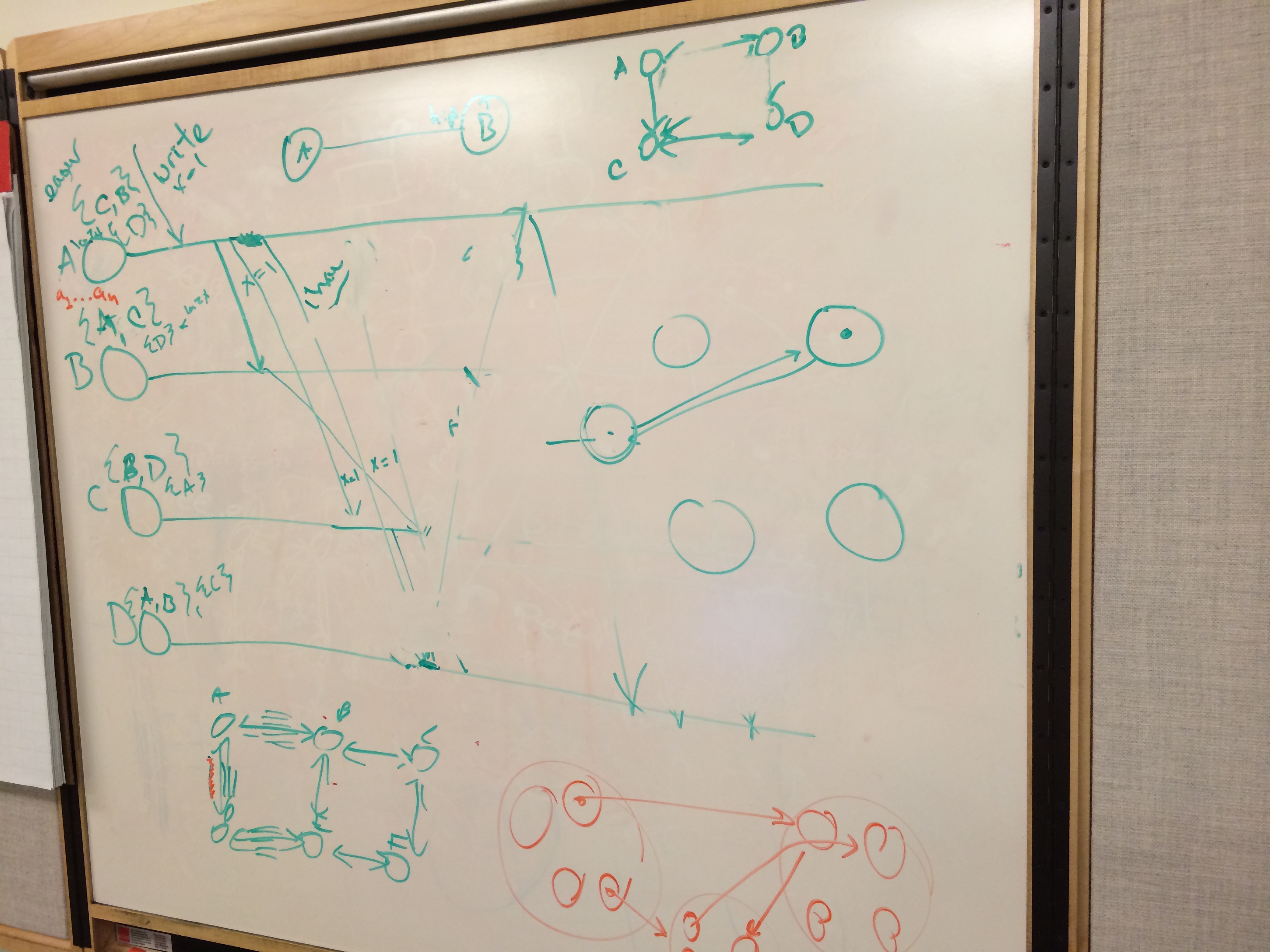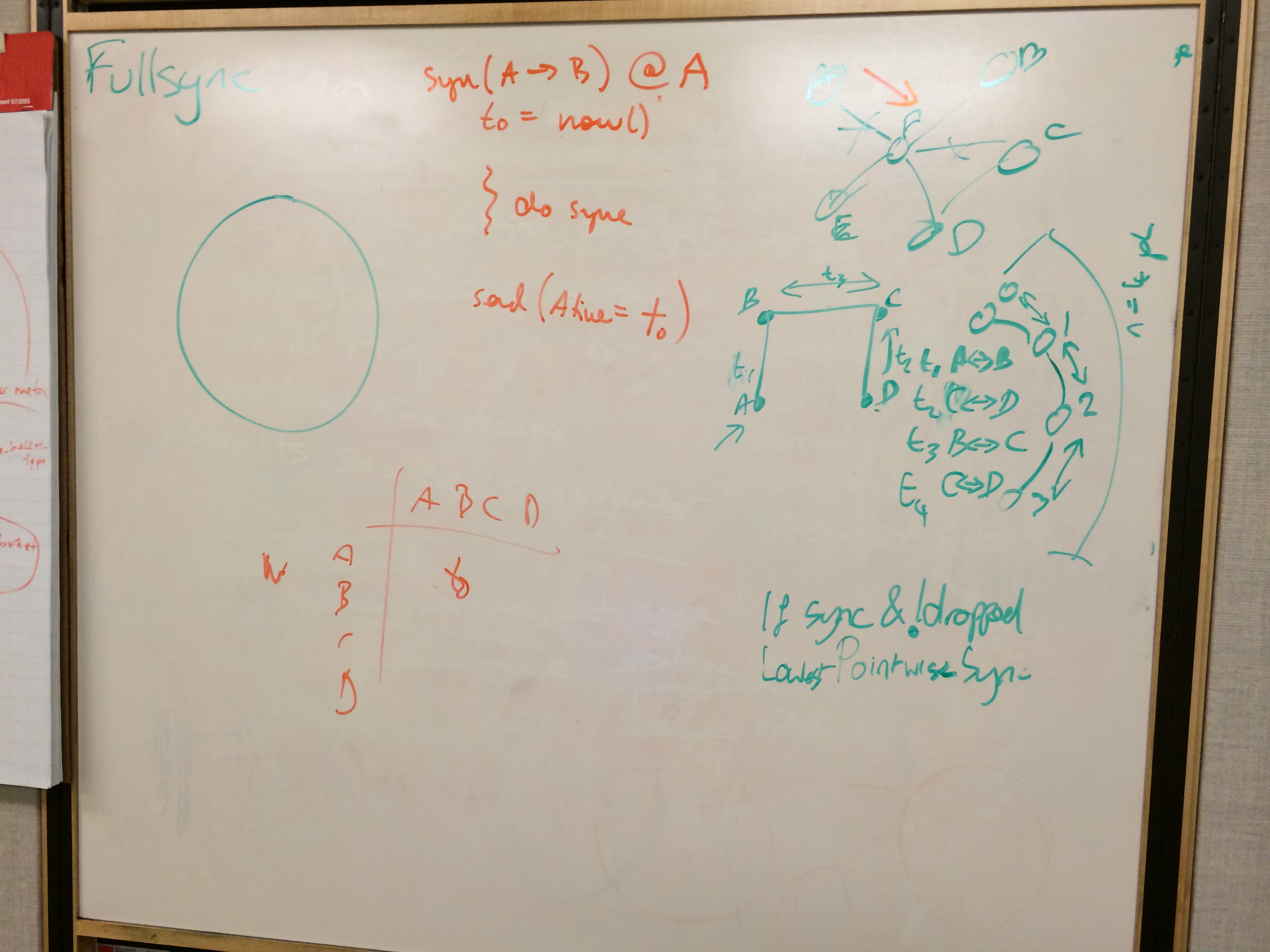MDC4 Kick Off Writeup
In person meetup in Bellevue, WA - August 20-22nd 2014.
Present
- Joe Blomstedt
- Jon Meredith
- Kresten Krab Thorup
- Micah Warren
- Jordan West
Recap
Wednesday afternoon was spent going over the replication system and talking through how each of the components worked whilst talking through the know techdebt/customer issues at the same time. Before the others arrived I got a chance to talk through the polynomial sync work with Kresten and he's also very excited by it.
As Fullsync is a big issue we spent a good long time talking through the current issues and worked out how we could iteratively improve it. Doing some code inspection we worked out the relative cost of our three variants on fullsync strategy and worked found an additional reason why AAE fullsync is so slow.
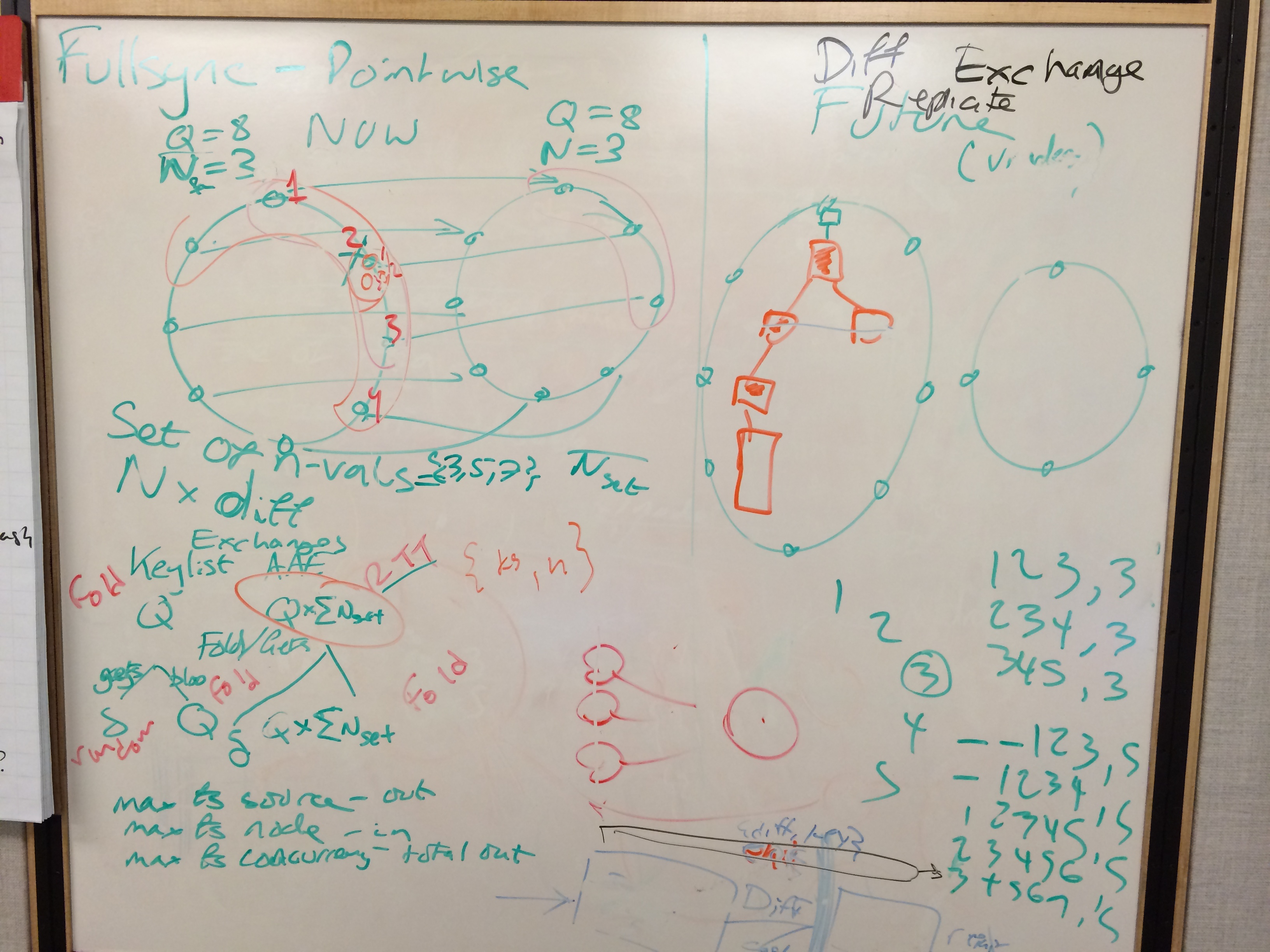
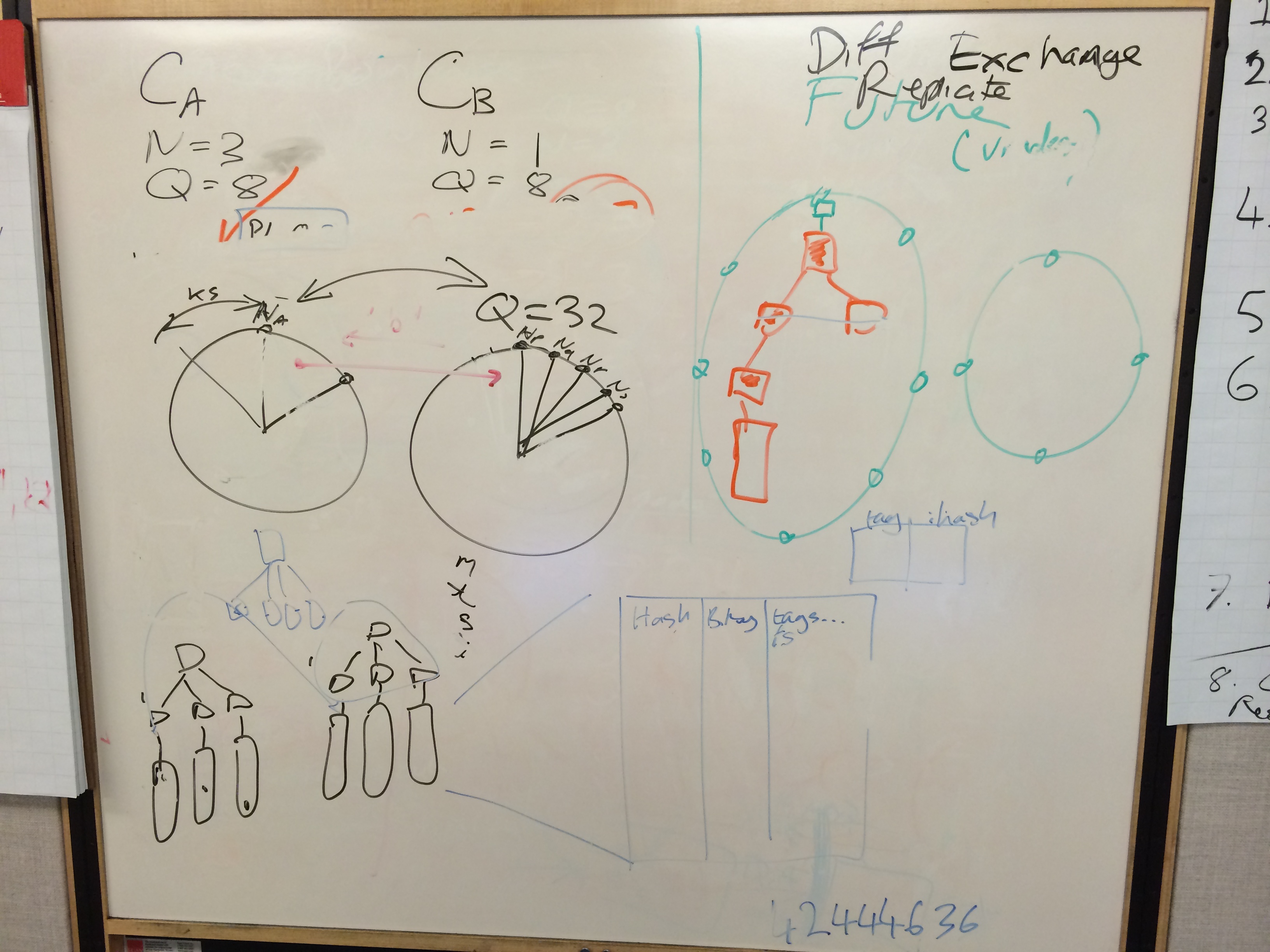
Kresten already pointed out that the way we send over differences isn't very efficient for small numbers of differences. We compute the exchanges (non-pipelined chatty sync request/response doesn't do well with high RTT), build a bloom filter and fold over all the backend data. We already knew the exchange was slow, but we discovered that the folding is more awful than we thought. On each vnode, we maintain separate AAE trees for each preference list the vnode is involved in (say nodes are ABCDE go around the ring, for a preference list at C we have a tree for an equivalent of ABC, BCD, CDE for each N-value). Because fullsync is currently vnode-based you have to exchange each of those trees. Instead of doing the individual exchanges and accumulating a single bloom filter then golding once, it folds for EACH tree. So if you had a cluster with some buckets N=3, some N=1 it would do exchange/fold for {C,1},{ABC,3},{BCD,3},{CDE,3}. That's a total of 4 full folds over the vnode if you discovered at least one difference in each.
We think for the 2.0.X series we can pipeline the AAE exchange and replace that multiple fold with a smarter abstraction that starts off just retrieving the data, then after a threshold of requests switches to the bloom/fold for more efficient bulk transfer.
Next we talked through ways to remove some of the limitiations we have with fullsync, discovered that the current AAE fullsync strategy has problems with forever resynchronizing buckets that have replication disabled (it never sends repl disabled buckets, so will always report the diff). We ended up with an algorithm that lets us fullsync between clusters with different ring size, bucket n-values and replication enabled/disabled settings. It requires some changes to the way we build the AAE trees, and just needs an incremental/commutative hash (either an arithmetic, multipilicative hash or the polynomial sync will work).
We also came up with a way for working out how synchronized the data is across all clusters and we should be able to provide a matrix that lets you know for data written in a given cluster, a worst case bound of when the last time the data was fully synchronized with each remote datacenter, which we can combine with the realtime drop info to answer the two very common customer questions.
-
Do I need to run a fullsync?
-
How up to date is my data?
We have that work broken up into units of work that we can plan iterations around, but it seems doable for 2.1 as one of our top priorities. Fullsync took more time than I'd hoped but I'm very satisfied with the outcome.
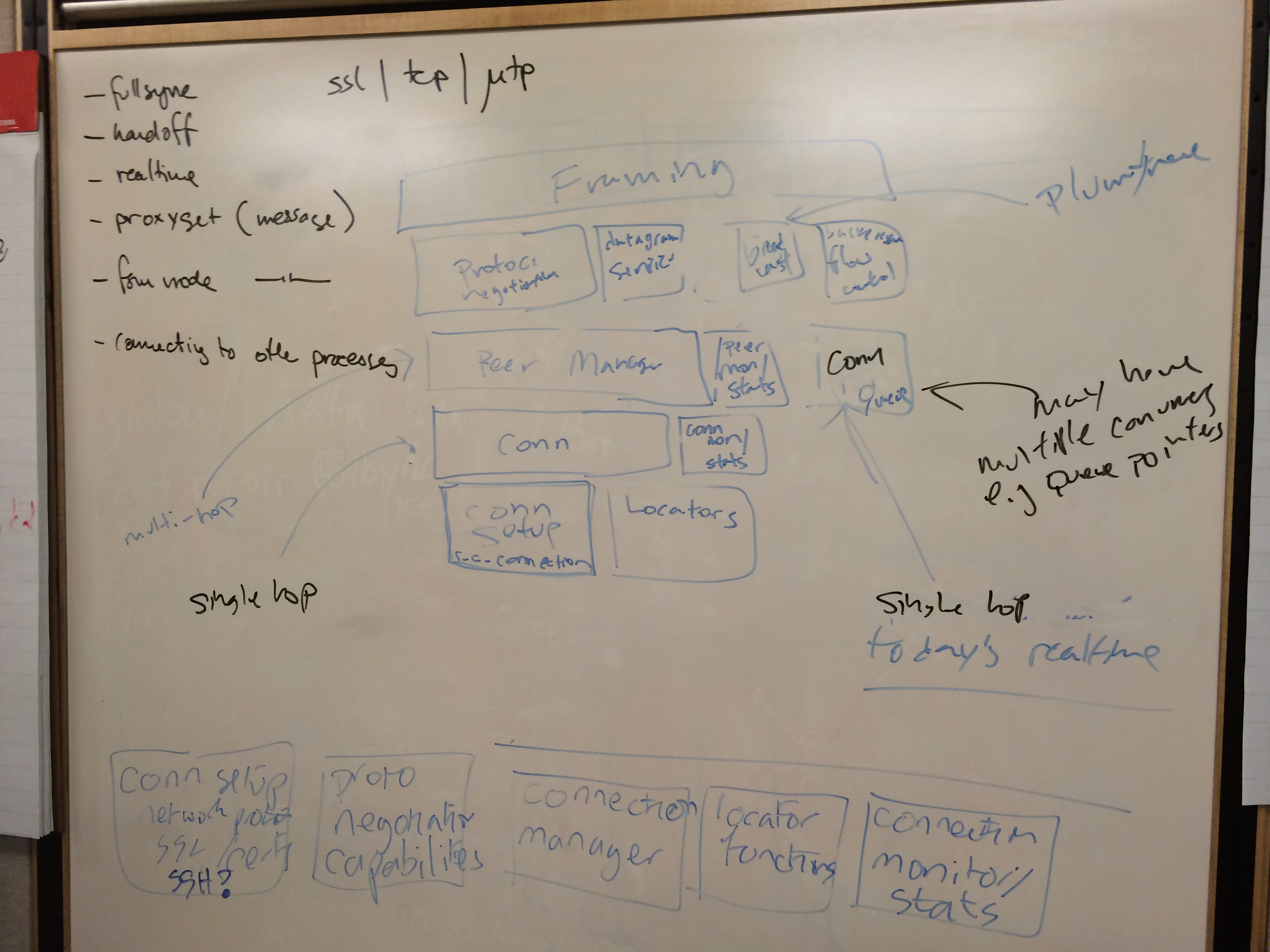
Friday morning we worked through the network sockets layer we have now, the tricks we've used for performance and problems, drew up a stack that we think would let us generalize parts of realtime that would be useful the rest of replication, but also other distribution problems. It's broken down into four larger epics at the moment and needs to be specified, further subdivided. I think that work is general enough to be the basis for the handoff work, a way of moving the request data path off of distributed erlang, and possibly the lowest layers of the data platform communication on the Riak side, I'll be talking it through with Steve and see how well the requirements match.
Next up was strong consistency. We worked out a global strong consistency system that reuses the existing riak_ensemble work by letting each cluster provide a configurable number of nodes to the concencus group. The nodes are addressed logically as {cluster_a, node1}, {cluster_a, node2} so each cluster is responsible for local placement and routing. We think you'd be able to dynamically change the number of copies at a site if you wanted, have a way for automatic leader election during failures and in cases where data became unavailable at a site have a way to manually mark a cluster as the authority with the caveat that we will discard modified data in other sites on reconnection. This was more important for the two-cluster case where you can't do quorums but also helps until you get to 5+ clusters for the byzantine stuff.
The plan would be to provide that as an additional type of bucket, so we would offer replicated eventually consistent (variable N-per cluster) KV & CRDTs, local-only strongly consistent (never replicated, availability is governed by local cluster only), global strongly consistent (guaranteed global strong consistency, higher latency as accesses are over WAN). We would just need to add global-ec and we can do all of the things, that would give us N-copies-in-the-world-at-the-cost-of-WAN-access-if-you-need-it
Joe is going to write up a description of how that will work, and from there we'll be able to work out what research remains and what we need to break it up into streams of work.
We had a discusstion about moving from cluster metadata to global metadata, and all agree it is a good thing (tm), giving us configure-for-everywhere bucket types and security. The idea discussed was to have a nominated 'admin' cluster that changes were forwarded to then propagated out from. You would have a hierarchy of configuration scope from global -> cluster -> node, and we would modify the bucket type/security code to check that changing the setting at that particulary scope is valid - for example the datatype/consistent settings could only be set at the global level, but nval could be set at the cluster level, and backend choice could be overridden at the node level.
Jordan is going to write up the description of that, what research remains and what we need to break it up into work. There's also a few smaller bits of work like balancing realtime replication connections and reporting some stats better
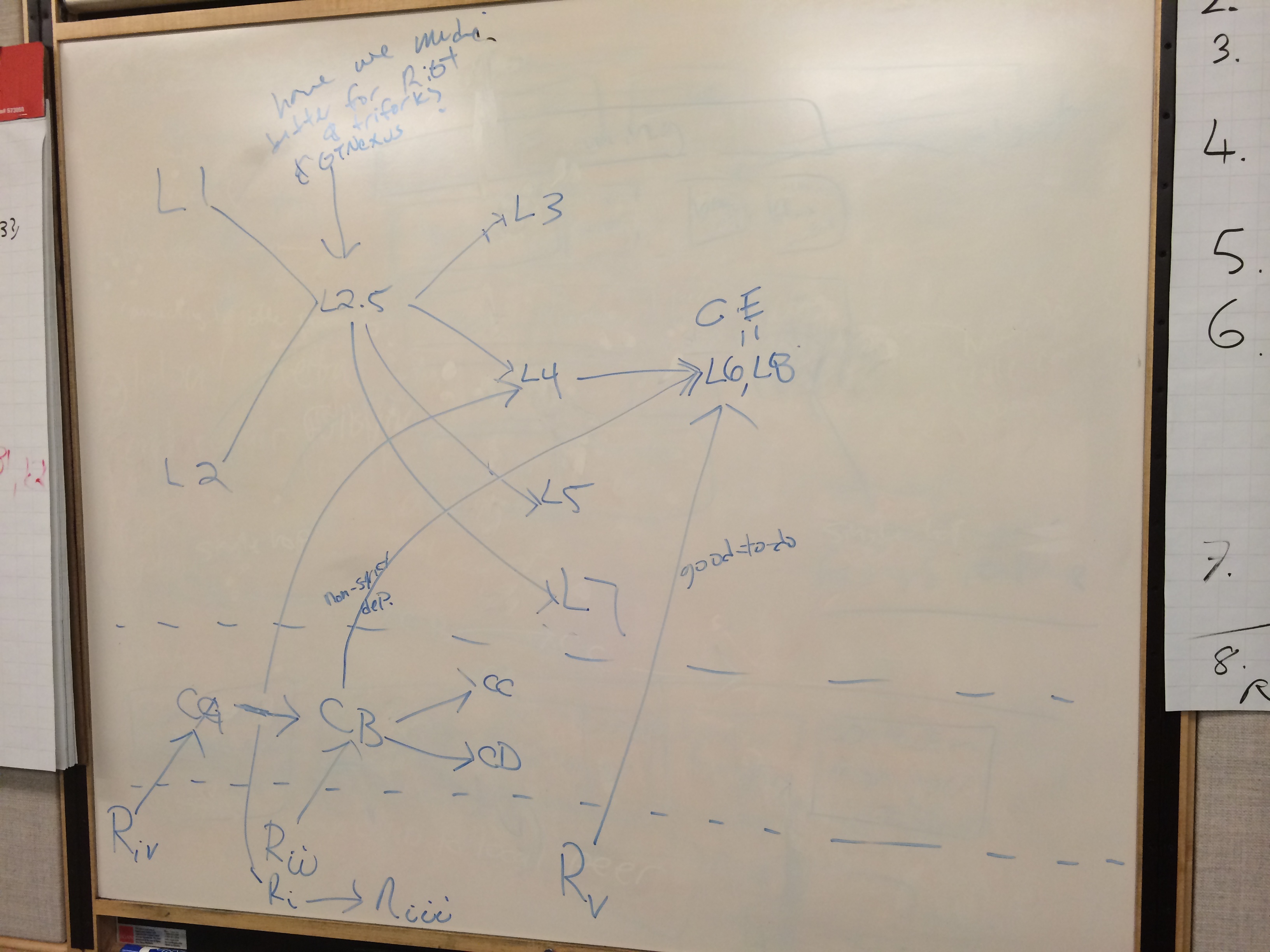
Our last thing we managed to work through was the dependencies between all of the work discussed for sequencing/parallelism. In the taxi ride to the airport we talked through some of the testing challenges and what we want to get out of it, I'll write that up.
The one topic we didn't get as far as I had hoped was background task management. A background management system was written for 2.0 but we didn't trust the engineer that did the work (same guy who caused a lot of the repl problems) so we've disabled the integration points by default for now.
We'll need to work out some tasks to do some coarse scheduling of work to prevent things like a vnode being hit by fullsync, aae rebuilding and ownership handoff all at the same time. It'll require some work to see what we can keep and what we need to rewrite in both the background manager itself and the integration points.
So as I said in the tl;dr,
- we have a way forward and relatively detailed planning for tasks to completely fix fullsync.
- high level ideas on a generalized networking layer we can use for replication, request data, handoff data, and possibly the data platform.
- high level design for global strong consistency
- high level design for global metadata
- a dependency graph of the high level chunks of research and work that delivers incremental improvements for 2.0.x and beyond.
- we'll need to do more thorough planning but it looks like we have a good shot at fixing at least fullsync, realtime balance and handoff for 2.1. The dependency graph and resource allocation determine if we can take on global SC and global metadata.
For work beyond 2.1 we should have pieces we need for moving the data path off distributed erlang and kv-as-crdt and enabling the data platform components.
It was a good few days of work.