Configuring and running Structural Preprocessing
In your XNAT_PBS_JOB_CONTROL directory (i.e. the path specified in the XNAT_PBS_JOB_CONTROL environment variable) there are several files that are used to control the submission process for the Structural Preprocessing pipeline. If you do not have the XNAT_PBS_JOB_CONTROL environment variable set and/or haven't installed the XNAT_PBS_JOBS tools and the XNAT_PBS_JOB_CONTROL files, please see Setting up to run CCF Pipeline Processing on the WUSTL CHPC Cluster
The control files used are:
-
SubmitStructuralPreprocessingBatch.ini- Used to specify job submission parameters such as:
- the stage of processing to complete (e.g.
PREPARE_SCRIPTS,GET_DATA,PROCESS_DATA,CLEAN_DATA,PUT_DATA, orCHECK_DATA) - the name of the output resource to create with the results (e.g.
Structural_preproc) - the resource limits for the processing job (e.g. Walltime limit, Memory Limit)
- the stage of processing to complete (e.g.
- Used to specify job submission parameters such as:
-
SubmitStructuralPreprocessingBatch.logging.conf- Used to configure how much logging or debugging information is presented to you during job submissions.
-
SubmitStructuralPreprocessingBatch.subjects- Used to specify the subjects for which to submit pipeline processing jobs when using the SubmitStructuralPreprocessingBatch application
-
StructuralPreprocessing.SetUp.sh- Contains environment variable settings and any other set up tasks that must be done before each submitted pipeline processing job can be run.
-
StructuralPreprocessingControl.subjects- Used to specify the list of subject to work with (submit jobs, check status, etc.) when using the StructuralPreprocessingControl application
Of these files, the .subjects files are the ones you'll likely be editing the most.
SubmitStructuralPreprocessingBatch.subjects - Specifying subjects for which to submit jobs using the SubmitStructuralPreprocessingBatch application
The SubmitStructuralPreprocessingBatch.subjects file contains a list of subjects for which to submit Structural Preprocessing pipeline jobs. The subjects are listed, one per line, in the following form:
<db-project>:<subject-id>:<classifier>:<scan-spec>
where <db-project> is the Database Project for the subject, <subject-id> is the subject's ID within the project, <classifier> is the session classifier (e.g. 3T or V1_MR) and <scan-spec> specifies the scan (or scans) to process.
An example subject specification would look like:
testproject:HCA6018857:V1_MR:all
This would mean that you want to submit pipeline processing jobs for the session classified as the V1_MR session for the subject with ID HCA6018857 in the testprojectt project. For some pipelines, the processing is done separately for each scan (e.g. rfMRI_REST1_RL would be processed separately from rfMRI_REST1_LR and separately from rfMRI_REST2_RL, etc.) In that case, you would need to specify the scan for which to submit jobs. In the case of Structural Preprocessing, there is no separate processing done for each scan or scan type, so for the field, we just use the all indicator.
The : delimiter is required. Any line in the subjects file that starts with a # (specifically has the # in the first column) is a treated as a comment. Blank lines are also ignored.
To specify a group of subjects for which to submit jobs for Structural Preprocessing, include a line like the above for each subject for which you want to submit jobs.
This file takes the same basic form as the SubmitStructuralPreprocessingBatch.subjects file described above. The difference is that these subjects will be used by the StructuralPreprocessingControl application. When using the StructuralPreprocessingControl application, you will be able to see the status of all subjects listed in this file with regard to running structural preprocessing. Note: The StructuralPreprocessingControl application allows you to open a specified subject list file. So you could simply open the SubmitStructuralPreprocessingBatch.subjects file in this application. But you'll probably want to keep the file specifying subjects to submit in batches separate from the file specifying subjects to work with in the control application.
This file contains bash statements that will be sourced before the each processing job. This is where you would specify the paths to things such as:
- The version/installation of Connectome Workbench to use
- The version/installation of FSL to use
- The version/installation of FreeSurfer to use
- The version/installation of the HCP Pipeline Scripts to use
- NOTE: THIS IS A FILE YOU SHOULD CHECK! YOU ARE LIKELY TO NEED TO VERIFY THAT THE HCPPIPEDIR ENVIRONMENT VARIABLE IS SET CORRECTLY!
The SubmitStructuralPreprocessingBatch.ini file is used to specify things such as resource limits, the stage of processing to submit jobs for, and the name of the database resource in which to place results.
It takes the form of a standard INI file. It will primarily consist of key-value pairs that look like:
key = value
For Structural Preprocessing, the relevant keys are:
CleanOutputFirst
This takes a boolean value (True or False) and determines whether an existing output resource in the XNAT database archive is removed before jobs are submitted. If the output resource is removed before processing begins, then if the processing fails (or fails to properly push its results into the database), then any previous results of running this pipeline will be lost.
WalltimeLimitHours
The processing job will be submitted with this value used as the walltime limit for the duration of the job. The value is specified in hours.
VmemLimitGbs
The processing job will be submitted with this value used as the virtual memory limit. The value is specified in GBs.
ProcessingStage
Indicates the stage of processing for which work should be done or jobs should be submitted. The possible values for this key are:
-
PREPARE_SCRIPTS- Create the processing directory for this run in the build space and write the scripts in that directory that would be submitted as jobs to the scheduler. But do not submit any of the jobs. -
GET_DATA- Prepare the scripts as above and submit a job to run the script that retrieves the input data for this processing and places it in the processing directory in the directory structure expected by the HCP Pipeline scripts (a.k.a. the "CinaB" structure). -
PROCESS_DATA- Prepare the scripts, submit the data retrieval job, and submit the job to actually run the Structural Preprocessing on the retrieved data. -
CLEAN_DATA- Prepare the scripts, submit the data retrieval job, submit the actual processing job, and submit a job to "clean" the data. "Cleaning" consists of removing any files from the "CinaB" directory structure that were neither modified nor newly created by the processing. -
PUT_DATA- Prepare scripts, retrieve data, do actual processing, clean the data, and submit a job to put the data into a session level resource for the subject. -
CHECK_DATA- Run the post-processing script that validates the structural preprocessing output. This "check data" script also adds to the output resource a file indicating whether the structural preprocessing has been validated as successfully complete and a file documenting what checks were done to determine if the structural preprocessing was successfully completed.
Note that these processing stages are an ordered list. This means that if you specify, for example, that processing should proceed through the CLEAN_DATA phase, all previous phases (PREPARE_SCRIPTS, GET_DATA, and PROCESS_DATA) will be run in sequence before the CLEAN_DATA phase.
Also note that the most common phase that should be specified here is the CHECK_DATA phase. Other phases would primarily be used during development and debugging of the submission process.
OutputResourceSuffix
Used to create the name of the session level resource in which the data is placed in the database. In the case of Structural Preprocessing, even though the key indicates that this is the "suffix" for the output resource, it is actually used as the full name of the output resource. In the case of pipelines that are run independently on different scans (e.g. tfMRI_REST1_LR, tfMRI_REST1_RL, tfMRI_REST2_LR, and tfMRI_REST2_LR may be processes independently through Functional Preprocessing), this value would actually be the "suffix" (e.g. preproc) added to the end of the output resource name (e.g. tfMRI_REST1_LR_preproc, tfMRI_REST1_RL_preproc, tfMRI_REST2_LR_preproc, tfMRI_REST2_RL_preproc).
Notice that each of these key values belongs in a section of the the INI file. (See the section discussion in the Wikipedia artical here. In the case of this INI file, the sections correspond to subject IDs. Anything specified in the [DEFAULT] section applies across subject IDs. But if, for example, a particular subject (say subject 100307) requires a higher walltime limit for this processing, that can be specified in a separate section of the INI file that looks something like:
[100307]
WalltimeLimitHours = 900
This file would primarily be used by a developer trying to debug the SubmitStructuralPreprocessingBatch.py application. Properly setting values in this file requires understanding the Python 3 standard logging mechanism. It's beyond the scope of this documentation to cover configuration of that logging mechanism.
To submit processing jobs for Structural Preprocessing first edit your ${XNAT_PBS_JOBS_CONTROL}/SubmitStructuralPreprocessingBatch.subjects file to reflect the subjects/sessions for which you want to submit jobs. Then issue the following commands:
$ cd ${XNAT_PBS_JOBS}
$ cd StructuralPreprocessing
$ ./SubmitStructuralPreprocessingBatch
When prompted, enter your database username and password (e.g. your ConnectomeDB username and password or your IntraDB username and password.)
The program will report as it reads the configuration file and reads the file specifying the subjects for which to submit jobs. Then it will report information about each subject for which it submits jobs. Submitting the jobs for one subject will look something like:
$ ./SubmitStructuralPreprocessingBatch
DB Username: tbbrown
DB Password:
Retrieving subject list from: /home/tbbrown/pipeline_tools/xnat_pbs_jobs_control/SubjectStructuralPreprocessingBatch.subjects
Reading configuration from file: /home/tbbrown/pipeline_tools/xnat_pbs_jobs_control/SubmitStructuralPreprocessingBatch.ini
-----
Submitting StructuralPreprocessing jobs for:
project: testproject
subject: HCA6054457
session classifier: V1_MR
put_server: http://intradb-shadow1.nrg.mir:8080
clean_output_first: False
processing_stage: ProcessingStage.CHECK_DATA
walltime_limit_hrs: 48
vmem_limit_gbs: 32
output_resource_suffix: Structural_preproc
brain_size: 150
Wed Aug 23 12:29:45 CDT 2017 - StructuralPreprocessing.MARK_RUNNING_STATUS - XNAT_PBS_JOBS:
/home/tbbrown/pipeline_tools/xnat_pbs_jobs Wed Aug 23 12:29:45 CDT 2017 - StructuralPreprocessing.MARK_RUNNING_STATUS - XNAT_PBS_JOBS_RUNNING_STATUS_DIR: /HCP/hcpdb/build_ssd/chpc/RUNNING_STATUS Wed Aug 23 12:29:45 CDT 2017 - StructuralPreprocessing.MARK_RUNNING_STATUS - Job started on login02.cluster at Wed Aug 23 12:29:45 CDT 2017 Wed Aug 23 12:29:45 CDT 2017 - StructuralPreprocessing.MARK_RUNNING_STATUS - ----- Platform Information: Begin ----- Linux login02.cluster 2.6.32-696.3.2.el6.centos.plus.x86_64 #1 SMP Tue Jun 20 08:34:26 UTC 2017 x86_64 x86_64 x86_64 GNU/Linux Wed Aug 23 12:29:45 CDT 2017 - StructuralPreprocessing.MARK_RUNNING_STATUS - ----- Platform Information: End ----- Wed Aug 23 12:29:45 CDT 2017 - StructuralPreprocessing.MARK_RUNNING_STATUS - project: testproject Wed Aug 23 12:29:45 CDT 2017 - StructuralPreprocessing.MARK_RUNNING_STATUS - subject: HCA6054457 Wed Aug 23 12:29:45 CDT 2017 - StructuralPreprocessing.MARK_RUNNING_STATUS - classifier: V1_MR Wed Aug 23 12:29:45 CDT 2017 - StructuralPreprocessing.MARK_RUNNING_STATUS - running status: TRUE Wed Aug 23 12:29:45 CDT 2017 - StructuralPreprocessing.MARK_RUNNING_STATUS - Complete
submitted jobs: ('GET_DATA', ['3234681.mgt2.cluster'])
submitted jobs: ('PROCESS_DATA', ['3234682.mgt2.cluster', '3234683.mgt2.cluster'])
submitted jobs: ('CLEAN_DATA', ['3234684.mgt2.cluster'])
submitted jobs: ('PUT_DATA', ['3234685.mgt2.cluster'])
submitted jobs: ('CHECK_DATA', ['3234686.mgt2.cluster'])
submitted jobs: ('Running Status', ['3234687.mgt2.cluster'])
-----
$
The sequence of job numbers submitted is reported in the submitted jobs: lines of the output. Dependencies are established between the jobs so that CHECK_DATA depends upon PUT_DATA completing successfully, PUT_DATA depends upon CLEAN_DATA completing successfully, etc. The Running Status job depends upon the CHECK_DATA job ending whether successfully or not.
To view the status of the submitted jobs, use a qstat command similar to the following:
$ qstat -u $USER
mgt2.cluster:
Req'd Req'd Elap
Job ID Username Queue Jobname SessID NDS TSK Memory Time S Time
----------------------- ----------- -------- ---------------- ------ ----- ------ ------ --------- - ---------
3234682.mgt2.cluster tbbrown pe1_168H HCA6054457.Struc 14719 1 1 32gb 48:00:00 R 00:30:39
3234683.mgt2.cluster tbbrown pe1_4H HCA6054457.Struc -- 1 1 4gb 04:00:00 H --
3234684.mgt2.cluster tbbrown pe1_4H HCA6054457.Struc -- 1 1 4gb 04:00:00 H --
3234685.mgt2.cluster tbbrown HCPput HCA6054457.Struc -- 1 1 12gb 04:00:00 H --
3234686.mgt2.cluster tbbrown pe1_4H HCA6054457.Struc -- 1 1 4gb 04:00:00 H --
3234687.mgt2.cluster tbbrown pe1_4H HCA6054457.Struc -- 1 1 4gb 04:00:00 H --
$
The first job in the list above (with job ID 3234682.mgt2.cluster or abbreviated as just 3234682) is the job that does the actual processing (the PROCESS_DATA job). The job that gets the data (the GET_DATA job) is relatively quick and has already completed. The second job in the list (3234683) is a second job in the actual processing which generates the FreeSurfer assessor. The third job in the list (3234684) is the the CLEAN_DATA job. The fourth job in the list (3234685) is the PUT_DATA job. (Notice that it is assigned to the HCPput queue.) The fifth job in the list (3234686) is the CHECK_DATA job. Finally, the sixth job in the list (3234687) is the Running Status job.
Common job status values (shown under the S heading) are:
- Q - queued. The job is ready to run and in the queue waiting the run. The job scheduler has not yet assigned resources to the job (processing node, memory, etc.) and started it running.
- R - running. The job has been assigned resources and is currently running.
- C - complete or completing. The job has finished but has not yet been removed from
qstats records. - H - held. The job is in the queue, but cannot run because a condition has been placed upon it that it must wait for in order to be allowed to be run. Typically, this condition is that it must wait for another job to complete.
You can get more information about a particular job by using the Job ID in a qstat -f <job-id> command like:
$ qstat -f 3234682
The CheckStructuralPreprocessingCompletionBatch application checks the status of structural preprocessing for subjects listed in the ${XNAT_PBS_JOBS_CONTROL}/CheckStructuralPreprocessingCompletionBatch.subjects file.
Using this application looks something like:
$ cd $XNAT_PBS_JOBS
$ cd StructuralPreprocessing
$ ./CheckStructuralPreprocessingCompletionBatch
Retrieving subject list from: /home/tbbrown/pipeline_tools/xnat_pbs_jobs_control/CheckStructuralPreprocessingCompletionBatch.subjects
Project Subject ID Classifier Prereqs Met Resource Exists Resource Date Complete Queued/Running
testproject HCA6018857 MR True --- False N/A False False
testproject HCA6018857 V1_MR True Structural_preproc True 2017-08-26 07:50:29 True False
testproject HCA6054457 V1_MR True Structural_preproc True 2017-08-28 15:45:44 False False
testproject HCA6072156 V1_MR True Structural_preproc True 2017-08-26 10:25:41 True False
$
In addition to writing this status output to the screen/terminal, a file named StructuralPreprocessing.status is also generated.
Both the header line and the lines that show the status for each subject/session are tab separated value (TSV) lines.
They are intended to be easily copied and pasted into a spreadsheet (e.g. Excel or Google Sheets) in order to share this status information with others. (Open the StructuralPreprocessing.status file in a text editor like gedit, select the entire file, copy the selection, and then paste it into a spreadsheet.)
Notice that the CheckStructuralPreprocessingPrereqsBatch application can be used to simply check whether prerequisites are met for a list of subjects/sessions for running Structural Preprocessing. This information is also included in the output from the CheckStructuralPreprocessingCompletionBatch application. So you may never need to run the CheckStructuralPreprocessingPrereqsBatch application.
Using the StructuralPreprocessingControl application to both check status and submit new processing jobs
The StructuralPreprocessingControl application is a small GUI application that can be used to both monitor the status of Structural Preprocessing jobs and launch Structural Preprocessing jobs. The primary input to the StructuralPreprocessingControl application is a subject/session list which is similar in form to the primary inputs to the CheckStructuralPreprocessingCompletionBatch application and the SubmitStructuralPreprocessingBatch application.
Start the the SubmitStructuralPreprocessingBatch application as follows:
$ cd $XNAT_PBS_JOBS
$ cd StructuralPreprocessing
$ ./StructuralPreprocessingControl
The initial GUI will look similar to:
Open a subjects file by selecting the File --> Open option and selecting a file to open. The file open dialog will default to looking in the directory specified in the XNAT_PBS_JOBS_CONTROL
environment variable. The file you are most likely to want to open is the StructuralPreprocessingControl.subjects. Once a subjects file is opened, the interface will show the status
information for all subjects/sessions listed in the file. It will look similar to:
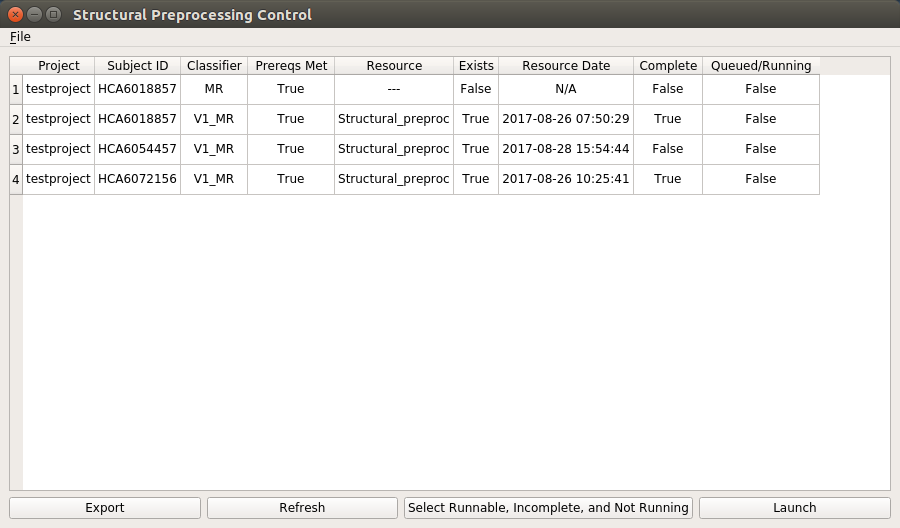
Notice that the columns of information are essentially the same as the columns of information that are provided in the output from the CheckStructuralPreprocessingCompletionBatch application.
You can export this information to a "status" file by selecting the Export button at the bottom of the display. You will be prompted to select/specify a file in which to store the
exported status information. This file will be in the same form as is produced by the CheckStructuralPreprocessingCompletionBatch application.
Since the status of Structural Preprocessing may change while this GUI application is running, you can select the Refresh button to completely refresh the status information for all
listed subject sessions.
The Launch operation will submit processing jobs to perform Structural Preprocessing for each of the currently selected rows of the status table. (If you have not selected any rows of the table,
you will be presented with a pop-up dialog telling you that you need to select some rows before you can launch jobs for them.)
The table works as you might expect in that you can select individual rows by clicking on them, select sequences of rows by clicking on one row and dragging down or up to another row to select
all the rows from the first row you selected to the second row that you dragged to. You can also Ctrl click to toggle a row between selected and unselected while not changing the
selected state of any of the other rows. Using these common row selection techniques you can select a set of rows for which you want to submit Structural Preprocessing jobs. After selecting
the rows, simply press the Launch button.
The application is not completely GUI in nature. When you select the Launch button, the same textual output you would see when using the SubmitStructuralPreprocessingBatch application
will be shown in the terminal window from which you launched the GUI. The launching process can take quite a while even when only a few subject sessions are selected. So it is worth
monitoring the output of the process in the terminal window.
Unlike the SubmitStructuralPreprocessingBatch application, the list of subject sessions for which to submit jobs will not come from a .subjects file. Instead it will be based upon
which subject sessions you've selected in the table in the GUI. The rest of the control of the submission process (resource limits, debugging information, processing stage, etc.)
will still be controlled by the same control files as are used for the SubmitStructuralPreprocessingBatch application.
When you select the Launch button with a set of rows selected, before submitting jobs for your selected
sessions, a popup dialog will ask you for your Username and Password. These are your Username and Password for the XNAT instance (e.g. ConnectomeDB or IntraDB) from which data is to be retrieved before running Structural Preprocessing and to which results are to be posted after running Structural Preprocessing.
After submitting processing jobs, the table will be refreshed with the current status for the listed subject sessions.
Note that a value of True in the Queued/Running column, does not mean that jobs are actually running on the CHPC cluster. The jobs could be queued to run, but not yet actually running on a cluster node.
Lastly, since it seems likely that it will be common to want to submit processing jobs for all subject sessions that have met the prerequisites (i.e. are Runnable), have not completed
processing, and are not currently queued or running, there is a button on the interface (Select Runnable, Incomplete, and Not Running) which selects all the rows in the table
that meet those three criteria. Once they are selected this way, you can submit jobs for them by pressing the Launch button.