This repository is a fork of the original project dominiek/word2vec-explorer. We removed the Cherrypy web framework and added Flask to the project. We also replaced the tsne library we use the t-SNE implementation provided by the Scikit-Learn framework.
The server now accepts in input a general pickled object that contains the embeddings. We also provide a script to convert gensim embeddings to their pickled version.
To install all Python depenencies:
pip install -r requirements.txtcreate a directory to manage converted models
mkdir model_filesRun the script that converts the embedding model into a pickled object
python3 convert_gensim_word2vec_model_to_embedding_file.py word2vec_file_pathpython3 server.py new_embedding_object_fileThis tool helps you visualize, query and explore Word2Vec models. Word2Vec is a deep learning technique that feeds massive amounts of text into a shallow neural net which can then be used to solve a variety of NLP and ML problems.
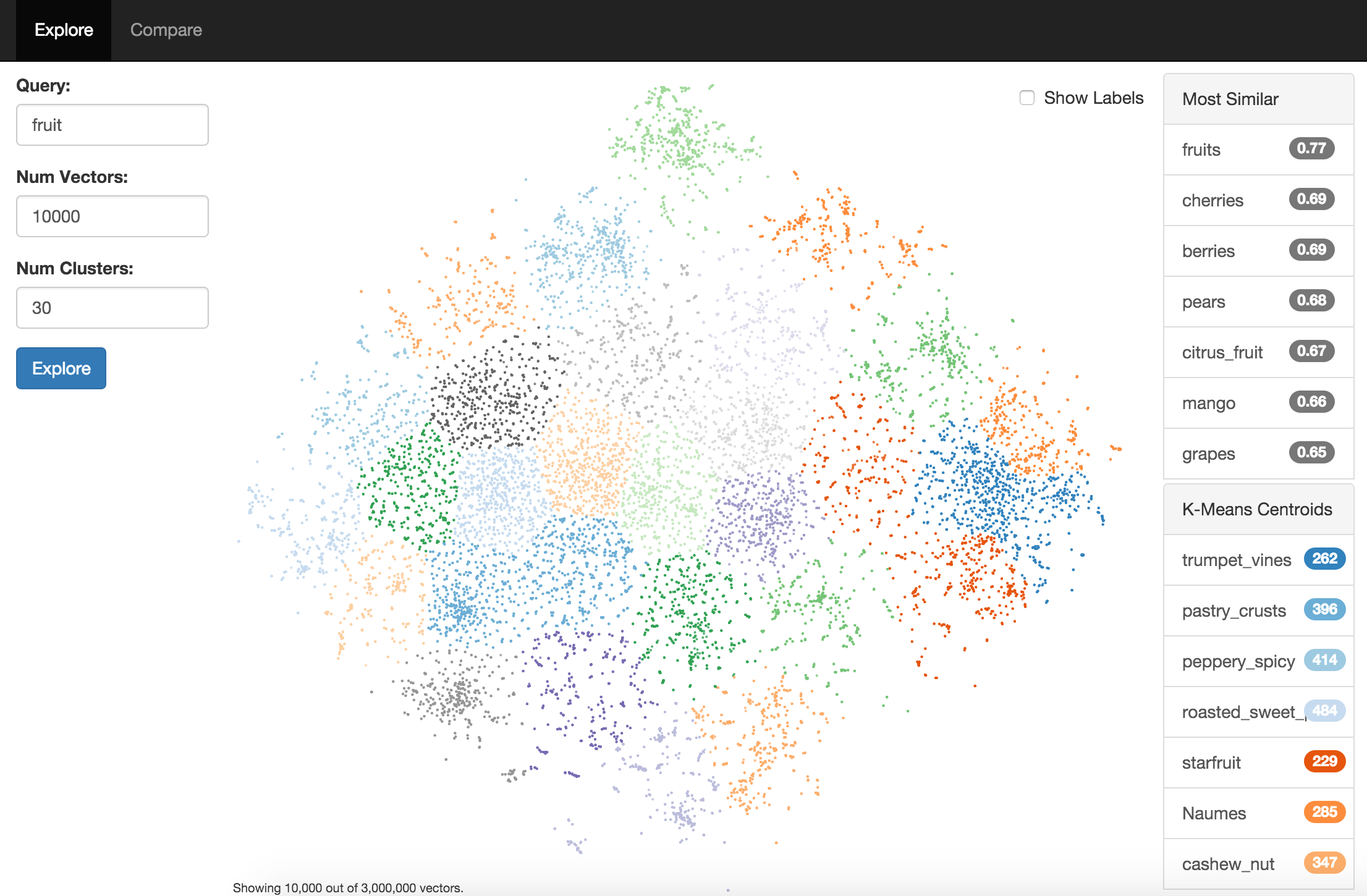
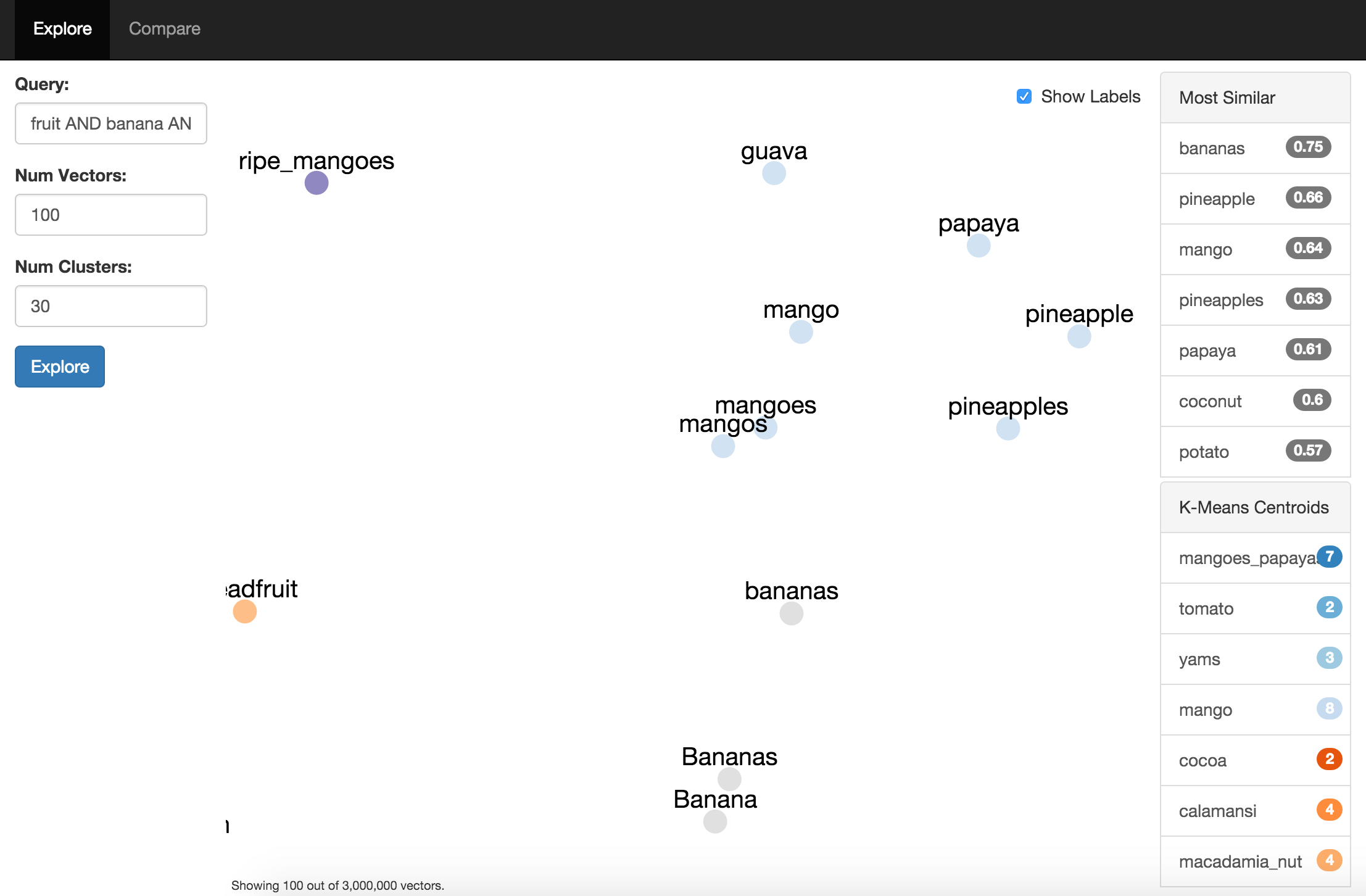
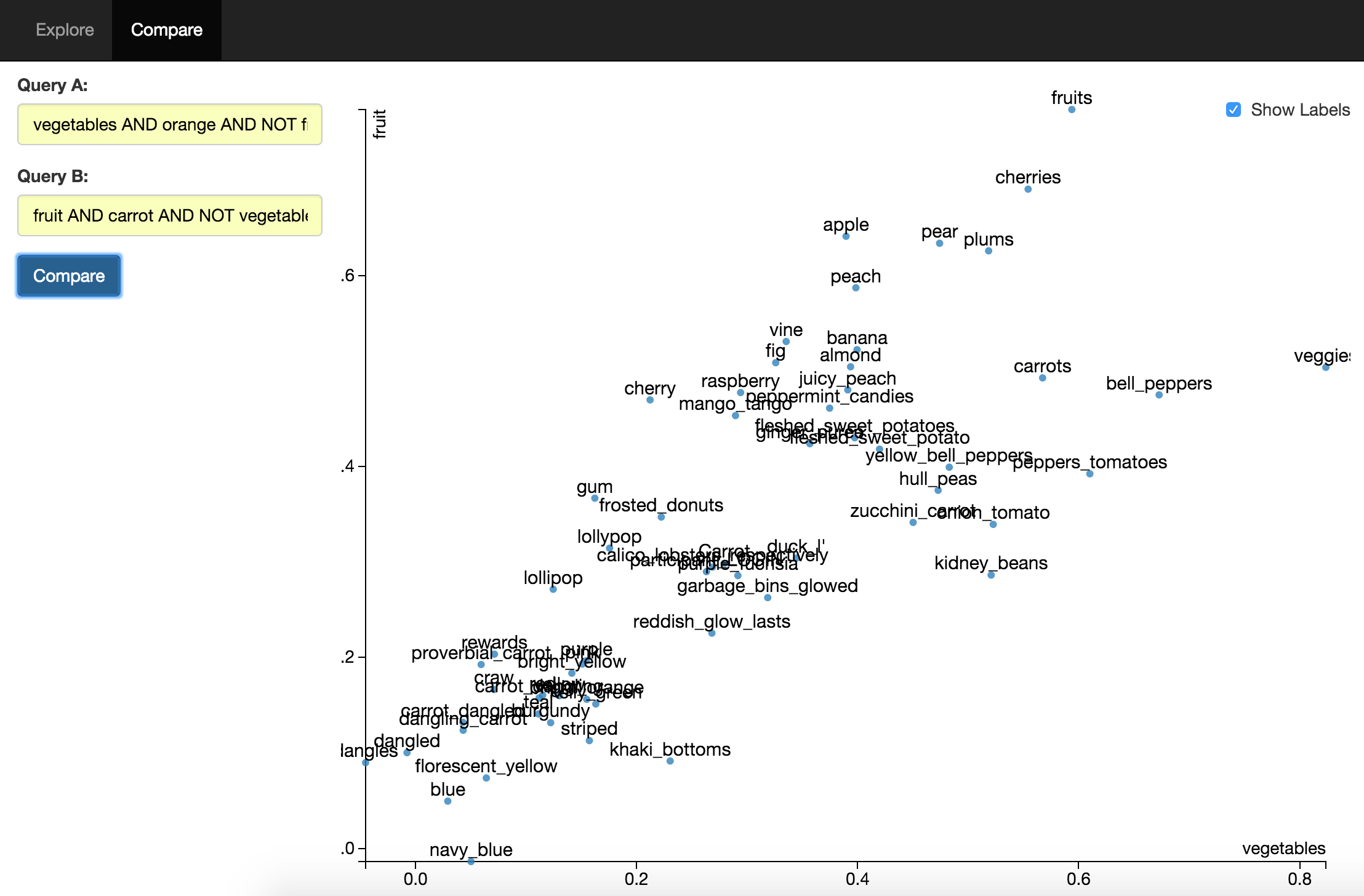
Word2Vec Explorer uses Gensim to list and compare vectors and it uses t-SNE to visualize a dimensional reduction of the vector space. Scikit-Learn is used for K-Means clustering.
The UI is built using React, Babel, Browserify, StandardJS, D3 and Three.js.
To install all Python depenencies:
pip install -r requirements.txtLoad the explorer with a Word2Vec model:
./explore GoogleNews-vectors-negative300.binNow point your browser at localhost:8080 to load the explorer!
A classic example of Word2Vec is the Google News model trained on 600M sentences: GoogleNews-vectors-negative300.bin.gz
[More pre-trained models]](https://github.com/3Top/word2vec-api#where-to-get-a-pretrained-models)
In order to make changes to the user interface you will need some NPM dependencies:
npm install
npm startThe command npm start will automatically transpile and bundle any code changes in the ui/ folder. All backend code can be found in explorer.py and ./explore.
Before submitting code changes make sure all code is compliant with StandardJS as well as Pep8:
standard
pep8 --max-line-length=100 *.py explore- 3D GPU/WebGL view (on branch
3d) - Make sure axes stay when zooming/panning scatterplot
- Autocomplete in query interface
- Look into supporting other high dimensional data models (go beyond word vectors)
- Drill-down of vector that shows real distance between neighbors
- Improved sample rated view that takes into account term counts and connectedness