{kind=link}
![]()
Full documentation: here
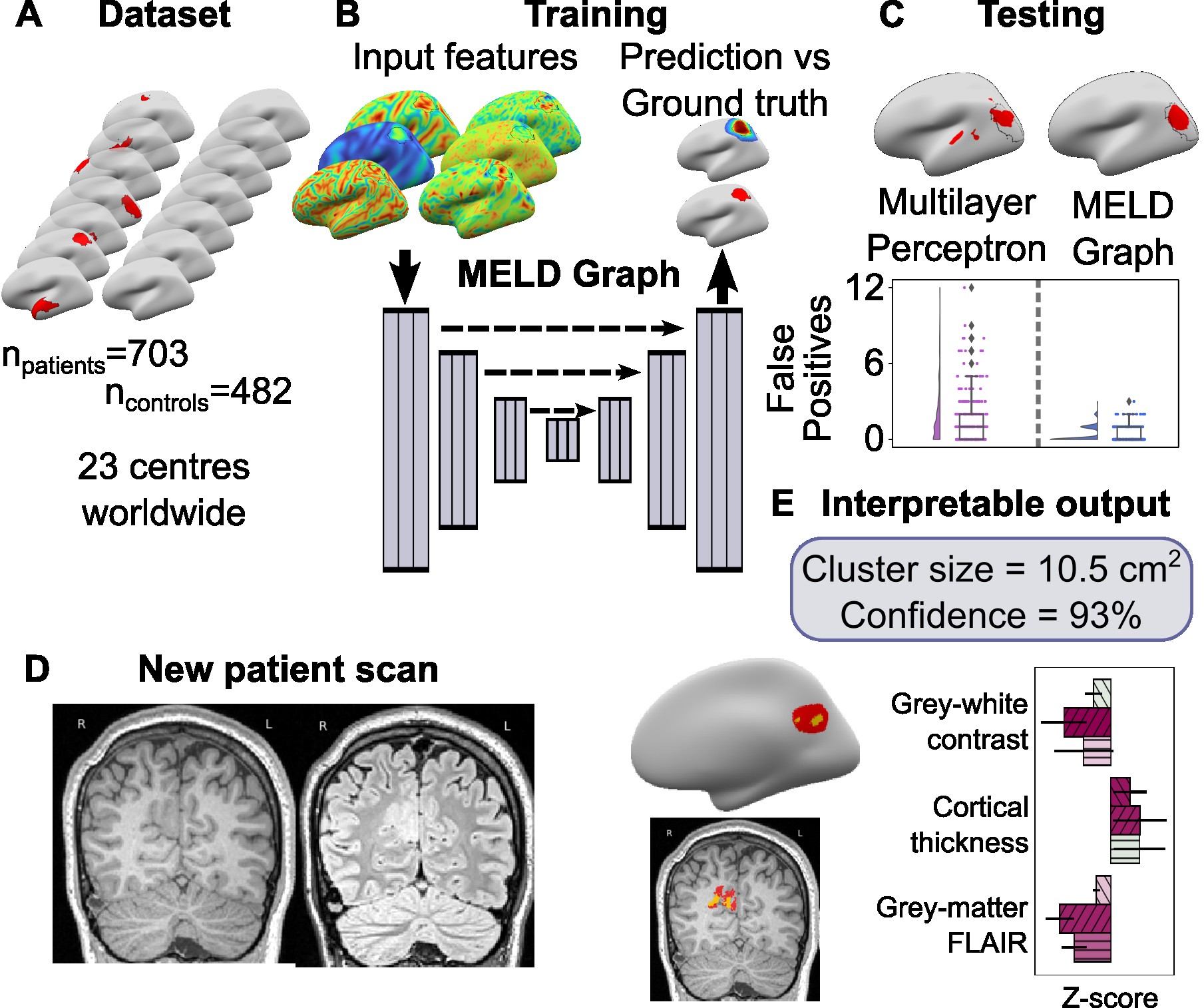
Graph based FCD lesion segmentation for the MELD project.
This package is a pipeline to segment FCD-lesions from MRI scans.
Code Authors : Mathilde Ripart, Hannah Spitzer, Sophie Adler, Konrad Wagstyl
This package is intended to be used as a research tool to segment FCD lesions in patients with focal epilepsy where a FCD is suspected. It can be run on 1.5T or 3T MRI data. A 3D T1 is required and it is optional but advised to include the 3D FLAIR.
It is not appropriate to use this algorithm on patients with:
- suspected hippocampal sclerosis
- hypothalamic hamartoma
- periventricular nodular heterotopia
- other focal epilepsy pathologies
** Harmonisation ** - MRI data from different MRI scanners looks subtly different. This means that feature measurements, e.g. cortical thickness measurements, differ depending on which MRI scanner a patient was scanned on. We harmonise features (using NeuroCombat) to adust for site based differences. We advise new users to harmonise data from their MRI scanner to the MELD graph dataset. Please follow the guidelines to harmonise the data from your site. Note: the model will still produce predictions on new, unharmonised subjects but the number of false positive predictions is higher if the data is not harmonised.
This package also contains code for training and evaluating graph-based U-net lesion segmentation models operating on icosphere meshes.
In addition to lesion segmentation, the model also contain auxiliary distance regression and hemisphere classification losses.
For more information on how the algorithm was developed and expected performance - check our papers:
- Ripart et al., under revisions at JAMA Neurology - Detection of epileptogenic focal cortical dysplasia using graph neural networks: a MELD study
- Spitzer, Ripart et al., 2022 Brain - the original MELD FCD pipeline and dataset
- Spitzer et al., 2023 MICCAI - the updated graph-based model architecture
The MELD surface-based graph FCD detection algorithm is intended for research purposes only and has not been reviewed or approved by the Medicines and Healthcare products Regulatory Agency (MHRA), European Medicine Agency (EMA) or by any other agency. Any clinical application of the software is at the sole risk of the party engaged in such application. There is no warranty of any kind that the software will produce useful results in any way. Use of the software is at the recipient's own risk.
You can install and use the MELD FCD prediction pipeline with :
- docker container (STILL IN PROGRESS) recommended for easy installation of the pipeline as all the prerequisite packages are already embeded into the container. Note: Dockers are not working on High Performance Computing (HCP) systems.
- native installation recommended for Mac and users that want to modify the code and/or use the code to train/test their own classifier.
- singularity container (COMING SOON) enables to run a container on High Performance Computing (HCP) systems.
Once installed you will be able to use the MELD FCD prediction pipeline on your data following the steps:
- Prepare your data : guidelines
- (OPTIONAL) Compute the harmonisation parameters : guidelines
- Run the prediction pipeline: guidelines
- Interpret the results: guidelines
What is the harmonisation process ?
Scanners can induce a bias in the MRI data. The MELD pipeline recommends adjusting for these scanners differences by running a preliminary harmonisation step to compute the harmonisation parameters for that specific scanner. Note: this step needs to be run only once, and requires data from at least 20 subjects acquired on the same scanner and demographic information (e.g age and sex). See harmonisation instructions for more details.
Note: The MELD pipeline can also be run without harmonisation, with a small drop in performance.
With the native installation of the MELD classifier you can reproduce the figures from our paper and train/evaluate your own models. For more details, check out the guides linked below:
If you'd like to contribute to this code base, have a look at our contribution guide
We would like to thank the MELD consortium for providing the data to train this classifier and their expertise to build this pipeline.
We would like to thank Lennart Walger and Andrew Chen, for their help testing and improving the MELD pipeline to v1.1.0.
We would like to thank Ulysses Popple for his help building the docs and dockers.
Contact the MELD team at [email protected]