- Draw an Entity Relationship Diagram (ERD) with crow's foot notation
- Identify and diagram one-to-one, one-to-many and many-to-many relationships between data entities
- Distinguish between entities and attributes
- Discuss data normalization needs and techniques
Concepts
- Explain what a database is and why you would use one
- Explain how a database, a database management system (DBMS) and SQL relate to one another
- Describe a database schema and how it relates to tables, rows and columns
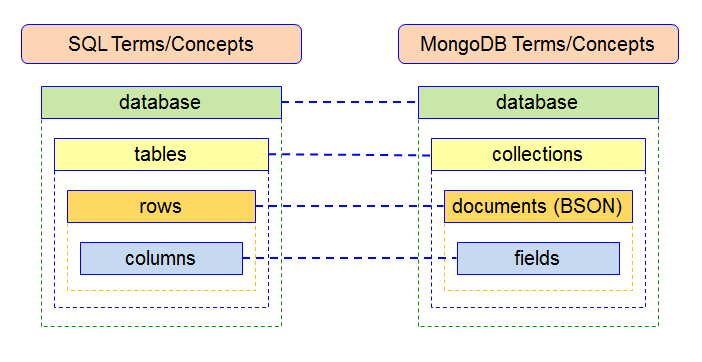
- Identify the differences between relational and non-relational databases
Mechanics
- Create a new PostgreSQL database
- Set up a PostgreSQL database schema with a saved SQL file
- Seed a PostgreSQL database with a saved SQL file
- Execute basic SQL commands to execute CRUD actions in a database
- Define what a foreign key is
- Describe how to represent a one-to-many relationship in SQL database
- Explain how to represent one-to-one and many-to-many relationships in a SQL DB
- Distinguish between keys, foreign keys, and indexes
- Describe the purpose of the JOIN
- Use JOIN to combine tables in a SELECT
- Describe what it means for a database to be normalized
A database is a place where information gets stored in a hard drive - or distributed across multiple hard drives - on a computer somewhere. Much like we've been creating and storing data, here and there, a database represents a collection of individual pieces of data stored in a highly structured and searchable way; they represent a model of reality, which why we call them models in MVC.
Inside a database, we do basic actions like create, read, update, and destroy data – CRUD!
In modern web development, there are different categories of databases – SQL, NoSQL, Key/Value.
Relational databases were invented in the 1970's as a way to structure data so that it can be queried by a "relational algebra." The basic idea of relational model, though, was to use collections of data, Tables, where each database manages Relations among the data in various tables. Each table is organized like a spreadsheet with a Row (also known as "record") for each data item and with attributes/fields of those items arranged in Columns.
- The majority of the databases people use everyday are relational databases, meaning they associate related pieces of data together, even if they are stored in different places (estimated to be around 79% in 2014)
- However, a fairly recent (< 10 years) development in databases is non-relational servers gaining market share. This is due to an increase in complexity of the data we need to structure, and the need for performance when operating on the DB
- SQL vs NoSQL:
- SQL is a relational database system, meaning it can store different types of information in multiple tables that are related together
- NoSQL is an alternative to SQL that stores information in key/value pairs. There is no concept of "tables" in NoSQL, just different values that can be accessed by certain keys
Developers employ user stories to clarify the features we need for a good user experience. What is a user story?
User stories are short, simple descriptions of a feature told from the perspective of the person who desires the new capability, usually a user or customer of the system. They typically follow a simple template:
As a
type of user, I wantsome goalso thatsome reason.
We use them to prioritize order and scope. This morning, we will identify the information required to support those user stories. We refer to this as the Domain or Domain Model. The Domain Model specifies the data and the relationships between this data. We use it to decide what needs to be persisted.
Domain Modeling allows us to outline the data values that we need to persist.
- We only consider the attributes of our data, not the behavior of our application
- A domain model in problem solving and software engineering is a conceptual model of all items and topics related to a specific problem
- It describes the various entities, their attributes, roles and relationships, plus the constraints that govern the problem domain
The big takeaway here is that domain modeling does not describe solutions to the problem. Instead, it defines how our data is structured.
An ERD -- or Entity Relationship Diagram -- is a tool we use to visualize and describe the data relating to the major entities that will exist in our programs.
- Ultimately lends itself to planning out and creating our database table structure
- It allows us to outline the data in our application, not the behavior
Relationships happen when we start seeing multiple duplicative information or when one object needs to "connect" to another object.
Note: Use the author/book/category example tables you've drawn to demonstrate creating relationships by making an ERD on the whiteboard; you should use crow's foot notation, making a point to demonstrate it on the board with our existing table drawings
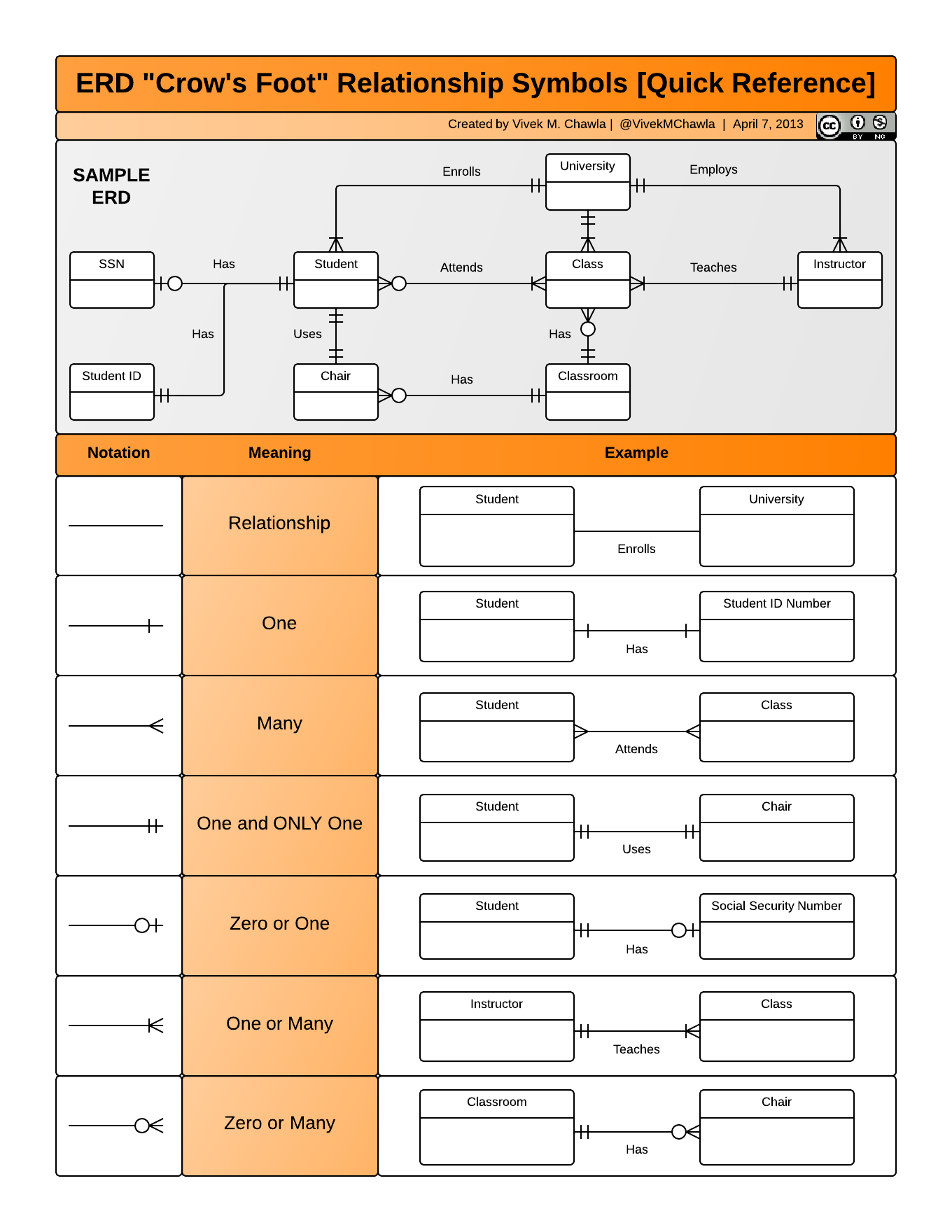
There are 3 different kinds of Relationships:
One-to-one: A Country has one Capital City
- not frequently used, but important to know it's an option
- imagine a Library table
has_onelocation, and a locationbelongs_toa specific library - that lets us look up solely by location, and see the connected library - often, in situations like that, you can make the location an attribute of the library, but when a location has, for example, multiple fields (address 1, address 2, state, zip, etc.), it might make sense to create another table for addresses and set up a
has_onerelationship- Usually denotes that one entity should be an attribute of the other
One-to-many: An author has_many books, but a book belongs_to only one author
- The most common relationship you will define in WDI.
Many-to-many: A book probably "has many" categories, and a category also probably "has many" books
- also very frequent
- Requires a join table.
Keep in mind, the
belongs_topart always goes on the opposite side of thehas_manyorhas_one. And the way it's stored is that the ID of the model that "has" something is stored in a field on the child, like "customer_id" or "author_id". In our example with authors and books, the Book modelbelongs_tothe Author model, while the Author, as mentioned,has_manybooks.
ERDs get more complex the larger your application becomes. Nevertheless, they are still a useful tool when planning and developing.
In Summary..
- The squares represent our entities and are filled with the attributes associated with our entity.
- The arrows between the squares indicate how the entities relate to one another.
SQL, Structured Query Language, is a specialized language used to create, manipulate, and query tables in relational databases.
-
Data Definition Language
- Define and update database's structure
- CREATE, ALTER, RENAME, DROP, TRUNCATE
- Data Types
- Constraints
-
Data Manipulation Language
- CRUD data within the database
- SELECT, INSERT, UPDATE, DELETE, ORDER BY
- UPSERT (attempts an UPDATE, or on failure, INSERT) is part of SQL 3 but not yet in Postgres
- Queries
- Aggregation: GROUP BY, SUM, AVG, MIN
-
Data Control Language (beyond our scope)
- GRANT access to parts of the table
Note that all these actions depend on what the database administrator sets for user permissions: a lot of times, as an analyst, for example, you'll only have access to retrieving company data; but as a developer, you could have access to all these commands and be in charge of setting the database permissions for your web or mobile application.
A database is just a repository to store the data and you need to use systems that dictate how the data will be stored and as a client to interact with the data. We call these systems "Database Management Systems", they come in many forms:
- MySQL
- SQLite
- PostgreSQL (what we'll be using!)
- pgAdmin: GUI for postgresql
...and all of these management systems use SQL (or some adaptation of it) as a language to manage data in the system.
They are all similar in that they use SQL, but they do have different features.
MySQL claims to be "the most popular open-source database," while PostgreSQL claims in response to be "the most advanced open-source database". It's true that in most tests, Postgres comes out ahead in terms of speed and has many features MySQL lacks, such as true full-text search and handling geo-data.
If you're interested in pros and cons, check out this article comparing MySQL, Postgres, and SQLite.
- Database - The actual set of data being stored. We may create multiple databases on our computer, usually one for each application.
- Database Language - The language used to interact with a database. With relational databases, that is SQL.
- Database Management System - The software that lets a user interact (query) the data in a database. Examples are PostgreSQL, MySQL, MongoDB, etc.
- Database CLI - A tool offered by most DBMSs that allows us to query the database from the command line. For PostgreSQL, we'll use
psql.
We'll use psql, which is a REPL for Postgres, a type of SQL database we have installed on our computers, as our primary means of interacting with our databases. Later on we'll use ruby or server-side JS programs to do so in our programs.
Here's a quick demo. Following along is optional.
Once Postgres is running, open your terminal and type:
$ psql
You should see something like: your_user_name=#
Great! You've entered the PostgreSQL equivalent of node: now, you can execute PSQL commands, or PostgreSQL's version of SQL.
help -- general help
\? -- help with psql commands
\h -- help with SQL commands
\l -- Lists all databases
\q -- quits
\d -- Lists all tables
\d+ table_name -- more info shownIn short...
- Backlash commands (e.g.
\l) are commands to navigate psql. These are psql-specific. - Everything else is SQL. The SQL is what actually interacts with the database.
If you're curious as to where exactly your databases are being stored locally, enter
SHOW data_directory;while in psql.
Let's create our first relational database (RDB) using the Terminal.
createdb practice
Then let's connect to it by name so we can practice our SQL.
psql practice
In your Terminal, you should see a prompt like the following:
practice=#
To quit/exit the database console, type:
\q
Console Tips
- Don't forget to close your SQL Commands with a semi-colon (";")!
- If you see
practice-#you're stuck in the middle of inputting a sql command (and likely forgot the trailing semi-colon). Just typectrl+cto start fresh.
To save your progress on the in-class examples and the challenges, I suggest creating files that store your SQL commands. To run a .sql file, use the following command in your terminal:
psql -f <file_name>
To run a sql file against a specific database, use:
psql -f <file_name> -d <database_name>
You can also create (and destroy) tables from within a SQL file. At the top of your SQL file, I suggest you write the following:
DROP DATABASE IF EXISTS database_name;
CREATE DATABASE database_name;Feel free to use the pqsl console to try out the following. Once you're comfortable with it, try using a .sql file.
If you would like to load, execute, and save .sql files in a safe, nurturing sandbox environment, head on over to this online SQL interpreter. It's handy!
Every application's database will have one or more tables. You will recall, each table stores information about a particular model (e.g., artists, songs).
Each table has a schema, which defines what columns it has. For each column the schema defines...
- The column's name.
- the column's data type.
- Any constraints for that column.
Here are some common data types for SQL DBs. They are all, for the most part, things you've seen before...
- Boolean
- Integer
- Float
- Text / VARCHAR
- VARCHAR is short, TEXT is long, CHAR(#) lets you set character length
- NULL
- Date
- Time
- Serial
- And many more...
Constraints act as limits on the data that can go in a column.
-
e.g.,
NOT NULLandUNIQUE. -
primary keys
-
foreign keys
-
unique
Now let's try to create our first Table within the new database. Note: please feel free to shorten attribute names so they're easier to type.
CREATE TABLE author (
id SERIAL primary key,
firstName VARCHAR(255),
year_of_birth INTEGER, /* also known as yob */
year_of_death NUMERIC DEFAULT 'NaN',
description TEXT,
created_at TIMESTAMP NOT NULL DEFAULT now()
);SERIAL TYPEPrimary KeyMORE DATA TYPES
We can ALTER this table after is created.
ALTER TABLE author ADD COLUMN last_name VARCHAR(255);An author doesn't need a description column, so let's remove it.
ALTER TABLE author DROP COLUMN description;Oops, Table names should always be plural. We'll fix the author table name.
ALTER TABLE author RENAME TO authors;Oops, it looks like our firstName column is camelCased. All column names should be snake_case. We can also rename columns.
ALTER TABLE authors RENAME COLUMN firstName TO first_name;Let's DROP our table!
DROP TABLE authors;The library's having a fundraiser! Here's another table we might have in the database:
CREATE TABLE products (
id SERIAL primary key,
name VARCHAR(255),
price NUMERIC NOT NULL DEFAULT 'NaN',
quantity INTEGER NOT NULL DEFAULT 0
);The most common SQL commands correspond to these 4 actions...
INSERT-> Create a rowSELECT-> Read / get information for rowsUPDATE-> Update a rowDELETE-> Destroy a row
How do we get data into a table? With INSERT!
INSERT INTO products
(name, price, quantity)
VALUES
('bookmark', 0.50, 200);Let's add a few more items to our products table
'book cover', 2.00, 75
'book bag', 60.00, 15
'reading light', 25.00, 10To retrieve data from inside our database, we use the command SELECT.
SELECT * FROM products;Let's look at only some attributes of each product.
SELECT name, price FROM products;We can use ORDER BY to sort the selected items.
SELECT name FROM products ORDER BY price;The WHERE keyword allows us to narrow down our query results. We can grab just the bookmark record.
SELECT * FROM products
WHERE name = 'bookmark';We can grab the more expensive items only.
SELECT * FROM products
WHERE price > 20.00
ORDER BY price;We can even use regular expressions to find products with "book" at the start of their names.
SELECT * FROM products
WHERE name LIKE 'book%';So far we've had a great time using SELECT to read data from our TABLE. We can also change data. Here comes our first sale, a bookmark!
UPDATE products
SET quantity = quantity - 1
WHERE name = 'bookmark';Let's also correct the spelling of book bag to bookbag.
UPDATE products
SET name = 'bookbag'
WHERE name = 'book bag';You might wonder why you don't see anything change after you update an entry. If you'd like, you can tell Postgres to return the modified record. It just isn't the standard behavior.
UPDATE products
SET quantity = quantity - 1
WHERE name = 'bookmark'
RETURNING *;Let's remove a row in our products table. Book covers don't sell that well.
DELETE FROM products
WHERE name = 'book cover'
RETURNING *;We could also DELETE everything but the bookmarks with the <> (not equal) operator.
DELETE FROM products
WHERE name <> 'bookmark';You can DELETE everything from a table using
DELETE FROM products;Challenge: Insert four items into the products table.

You can make your queries easier to read using an alias. Aliases in SQL use the keyword AS.
SELECT * FROM products
AS prod -- alias for the products table
WHERE prod.name = 'bookmark';SELECT name, price AS cost, quantity -- alias for the price column only
FROM products
WHERE name = 'bookmark';Note also that -- starts a SQL comment.
We can use selection to filter out rows that aren't distinct. First, let's add duplicate bookbag records.
INSERT INTO products
(name, price, quantity)
VALUES
('bookbag', 50.00, 20),
('bookbag', 65.00, 10);Then we'll select, looking for records with distinct names. Which of the bookbag records do you think will be selected?
SELECT DISTINCT ON (name) *
FROM products;SELECT SUM(quantity) AS total_inventory_count from products;
SELECT name, MIN(price) AS lowest_available_price
FROM products
GROUP BY name
ORDER BY lowest_avaialable_price;- All statements end in a semicolon.
- Whitespace doesn't matter.
- Uppercasing!
- Always use single quotes when typing out string values.
- Ye olde style guide.
One of the key features of relational databases is that they can represent relationships between rows in different tables.
Going back to our library example, we have two tables: books and authors. Our goal now is to somehow indicate the relationship between a book and an author. In this case, that relationship indicates who wrote the book.
You can imagine that we'd like to use this information in a number of ways, such as...
- Getting the author information for a given book.
- Getting all books written by a given author.
- Searching for books based on attributes of the author (e.g., all books written by a Chinese author).
How might we represent this information in our database? For this example, let's assume that each book has only one author (even though that's not always the case in the real world.)
authors
- name
- nationality
- birth_year
books
- title
- pub_date
- author_name
- author_nationality
- author_birth_year
What's the problem here?
Duplication, difficult to keep data in sync.
authors
- name
- nationality
- book_ids
books
- title
- pub_date
What's the problem here?
Parsing list, can't index (for speed!)
authors
- name
- nationality
books
- title
- pub_date
- author_id

To SELECT information on two or more tables at ones, we can use a JOIN clause. This will produce rows that contain information from both tables. When JOINing two or more tables, we have to tell the database how to 'match up' the rows. (e.g. to make sure the author information is correct for each book).
This is done using the ON clause, which specifies which properties to match.
SELECT id FROM authors where name = 'J.K. Rowling';
SELECT * FROM books where author_id = 2;
SELECT * FROM books JOIN authors ON books.author_id = authors.id;
SELECT * FROM books JOIN authors ON books.author_id = authors.id WHERE authors.nationality = 'United States of America';See advanced_queries.sql in the library_sql exercise.
There are actually a number of ways to join multiple tables with JOIN, if
you're really curious, check out this article:
A visual explanation of SQL Joins
We're not going to go in-depth with many-to-many relationships today, but lets go over a simple example...
Consider if we wanted to add a categories model (e.g. fiction, non-fiction, sci-fi, romance, etc). Books can belong to many categories (i.e. a book might be a fiction/romance, or a history/non-fiction). And a given category might have many books.
Because of this, we can't put a book_id column on categories, nor a category_id column on books, either way, we might have more than one value in that field (a no-no in terms of performance).
To solution is to create an additional table, which stores just the relationships between the two tables. Such a table is called a join table, and contains two foreign key columns.
In our example, we might create a table called 'categorizations', and it would have a book_id and category_id. Each row would represent a specific book's association with a specific category.
