第09期Datawhale组队学习计划马上就要开始啦!
本次组队学习的内容为:
大家可以根据我们的开源内容进行自学,也可以加入我们的组队学习一起来学。
开源内容:https://github.com/datawhalechina/team-learning-program/tree/master/DataStructureAndAlgorithm
- 贡献人员:马燕鹏、苏鹏、高永伟
- 学习周期::9天,每天平均花费时间3小时-5小时不等,根据个人学习接受能力强弱有所浮动。
- 学习形式:理论学习 + 练习
- 人群定位:有编程语言基础知识,熟悉面向对象程序设计。
- 先修内容:C#语言 或者 Python编程语言
- 难度系数:中
理论部分
- 理解数组的存储与分类。
- 实现动态数组,该数组能够根据需要修改数组的长度。
练习部分
1. 利用动态数组解决数据存放问题
编写一段代码,要求输入一个整数N,用动态数组A来存放2~N之间所有5或7的倍数,输出该数组。
示例:
输入:
N = 100
输出:
5 7 10 14 15 20 21 25 28 30 35 40 42 45 49 50 55 56 60 63 65 70 75 77 80 84 85 90 91 95 98 1002. 托普利茨矩阵问题
https://leetcode-cn.com/problems/toeplitz-matrix/
如果一个矩阵的每一方向由左上到右下的对角线上具有相同元素,那么这个矩阵是托普利茨矩阵。
给定一个M x N的矩阵,当且仅当它是托普利茨矩阵时返回True。
示例1:
输入:
matrix = [
[1,2,3,4],
[5,1,2,3],
[9,5,1,2]
]
输出: True
解释:
在上述矩阵中, 其对角线为:
"[9]", "[5, 5]", "[1, 1, 1]", "[2, 2, 2]", "[3, 3]", "[4]"。
各条对角线上的所有元素均相同, 因此答案是`True`。示例2:
输入:
matrix = [
[1,2],
[2,2]
]
输出: False
解释:
对角线"[1, 2]"上的元素不同。说明:
- matrix 是一个包含整数的二维数组。
- matrix 的行数和列数均在 [1, 20]范围内。
- matrix[i][j] 包含的整数在 [0, 99]范围内。
进阶:
- 如果矩阵存储在磁盘上,并且磁盘内存是有限的,因此一次最多只能将一行矩阵加载到内存中,该怎么办?
- 如果矩阵太大以至于只能一次将部分行加载到内存中,该怎么办?
3. 三数之和
https://leetcode-cn.com/problems/3sum/
给定一个包含 n 个整数的数组nums,判断nums中是否存在三个元素a,b,c,使得a + b + c = 0?找出所有满足条件且不重复的三元组。
注意:答案中不可以包含重复的三元组。
示例:
给定数组 nums = [-1, 0, 1, 2, -1, -4],
满足要求的三元组集合为:
[
[-1, 0, 1],
[-1, -1, 2]
]理论部分
- 理解线性表的定义与操作。
- 实现顺序表。
- 实现单链表、循环链表、双向链表。
练习部分
1. 合并两个有序链表
https://leetcode-cn.com/problems/merge-two-sorted-lists/
将两个有序链表合并为一个新的有序链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
示例:
输入:1->2->4, 1->3->4
输出:1->1->2->3->4->42. 删除链表的倒数第N个节点
https://leetcode-cn.com/problems/remove-nth-node-from-end-of-list/
给定一个链表,删除链表的倒数第 n 个节点,并且返回链表的头结点。
示例:
给定一个链表: 1->2->3->4->5, 和 n = 2.
当删除了倒数第二个节点后,链表变为 1->2->3->5.说明:给定的 n 保证是有效的。
进阶:你能尝试使用一趟扫描实现吗?
3. 旋转链表
https://leetcode-cn.com/problems/rotate-list/
给定一个链表,旋转链表,将链表每个节点向右移动k个位置,其中k是非负数。
示例 1:
输入: 1->2->3->4->5->NULL, k = 2
输出: 4->5->1->2->3->NULL
解释:
向右旋转 1 步: 5->1->2->3->4->NULL
向右旋转 2 步: 4->5->1->2->3->NULL示例 2:
输入: 0->1->2->NULL, k = 4
输出: 2->0->1->NULL
解释:
向右旋转 1 步: 2->0->1->NULL
向右旋转 2 步: 1->2->0->NULL
向右旋转 3 步: 0->1->2->NULL
向右旋转 4 步: 2->0->1->NULL理论部分
- 用数组实现一个顺序栈。
- 用链表实现一个链栈。
- 理解递归的原理。
练习部分
1. 根据要求完成车辆重排的程序代码
假设一列货运列车共有n节车厢,每节车厢将停放在不同的车站。假定n个车站的编号分别为1至n,货运列车按照第n站至第1站的次序经过这些车站。车厢的编号与它们的目的地相同。为了便于从列车上卸掉相应的车厢,必须重新排列车厢,使各车厢从前至后按编号1至n的次序排列。当所有的车厢都按照这种次序排列时,在每个车站只需卸掉最后一节车厢即可。
我们在一个转轨站里完成车厢的重排工作,在转轨站中有一个入轨、一个出轨和k个缓冲铁轨(位于入轨和出轨之间)。图(a)给出一个转轨站,其中有k个(k=3)缓冲铁轨H1,H2 和H3。开始时,n节车厢的货车从入轨处进入转轨站,转轨结束时各车厢从右到左按照编号1至n的次序离开转轨站(通过出轨处)。在图(a)中,n=9,车厢从后至前的初始次序为5,8,1,7,4,2,9,6,3。图(b)给出了按所要求的次序重新排列后的结果。
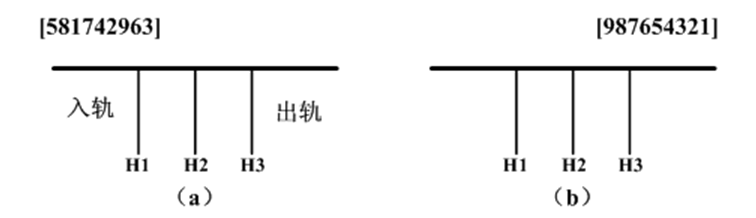
编写算法实现火车车厢的重排,模拟具有n节车厢的火车“入轨”和“出轨”过程。
理论部分
- 用数组实现一个顺序队列。
- 用数组实现一个循环队列。
- 用链表实现一个链式队列。
练习部分
1. 模拟银行服务完成程序代码。
目前,在以银行营业大厅为代表的窗口行业中大量使用排队(叫号)系统,该系统完全模拟了人群排队全过程,通过取票进队、排队等待、叫号服务等功能,代替了人们站队的辛苦。
排队叫号软件的具体操作流程为:
- 顾客取服务序号
当顾客抵达服务大厅时,前往放置在入口处旁的取号机,并按一下其上的相应服务按钮,取号机会自动打印出一张服务单。单上显示服务号及该服务号前面正在等待服务的人数。
- 服务员工呼叫顾客
服务员工只需按一下其柜台上呼叫器的相应按钮,则顾客的服务号就会按顺序的显示在显示屏上,并发出“叮咚”和相关语音信息,提示顾客前往该窗口办事。当一位顾客办事完毕后,柜台服务员工只需按呼叫器相应键,即可自动呼叫下一位顾客。
编写程序模拟上面的工作过程,主要要求如下:
- 程序运行后,当看到“请点击触摸屏获取号码:”的提示时,只要按回车键,即可显示“您的号码是:XXX,您前面有YYY位”的提示,其中XXX是所获得的服务号码,YYY是在XXX之前来到的正在等待服务的人数。
- 用多线程技术模拟服务窗口(可模拟多个),具有服务员呼叫顾客的行为,假设每个顾客服务的时间是10000ms,时间到后,显示“请XXX号到ZZZ号窗口!”的提示。其中ZZZ是即将为客户服务的窗口号。
理论部分
- 用数组实现一个顺序的串结构。
- 为该串结构提供丰富的操作,比如插入子串、在指定位置移除给定长度的子串、在指定位置取子串、连接串、串匹配等。
练习部分
1. 无重复字符的最长子串
https://leetcode-cn.com/problems/longest-substring-without-repeating-characters/
给定一个字符串,请你找出其中不含有重复字符的最长子串的长度。
示例1
输入: "abcabcbb"
输出: 3
解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。示例2
输入: "bbbbb"
输出: 1
解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。示例3
输入: "pwwkew"
输出: 3
解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。
请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。2. 串联所有单词的子串
https://leetcode-cn.com/problems/substring-with-concatenation-of-all-words/
给定一个字符串s和一些长度相同的单词 words。找出 s 中恰好可以由 words 中所有单词串联形成的子串的起始位置。
注意子串要与 words 中的单词完全匹配,中间不能有其他字符,但不需要考虑 words 中单词串联的顺序。
示例1
输入:
s = "barfoothefoobarman",
words = ["foo","bar"]
输出:[0,9]
解释:
从索引 0 和 9 开始的子串分别是 "barfoo" 和 "foobar" 。输出的顺序不重要, [9,0] 也是有效答案。示例2
输入:
s = "wordgoodgoodgoodbestword",
words = ["word","good","best","word"]
输出:[]3. 替换子串得到平衡字符串
https://leetcode-cn.com/problems/replace-the-substring-for-balanced-string/
有一个只含有'Q', 'W', 'E','R'四种字符,且长度为 n的字符串。假如在该字符串中,这四个字符都恰好出现n/4次,那么它就是一个「平衡字符串」。
给你一个这样的字符串 s,请通过「替换一个子串」的方式,使原字符串 s变成一个「平衡字符串」。你可以用和「待替换子串」长度相同的任何其他字符串来完成替换。
请返回待替换子串的最小可能长度。
如果原字符串自身就是一个平衡字符串,则返回 0。
示例1:
输入:s = "QWER"
输出:0
解释:s 已经是平衡的了。示例2:
输入:s = "QQWE"
输出:1
解释:我们需要把一个 'Q' 替换成 'R',这样得到的 "RQWE" (或 "QRWE") 是平衡的。示例3:
输入:s = "QQQW"
输出:2
解释:我们可以把前面的 "QQ" 替换成 "ER"。 示例4:
输入:s = "QQQQ"
输出:3
解释:我们可以替换后 3 个 'Q',使 s = "QWER"。开源内容:https://github.com/datawhalechina/team-learning-data-mining/tree/master/MachineLearningFundamentals
- 贡献人员:肖然、谢文昕、高立业
- 学习周期:11天,每天平均花费时间3小时-5小时不等,根据个人学习接受能力强弱有所浮动。
- 学习形式:理论学习 + 练习
- 人群定位:有概率论、矩阵运算、求导、泰勒展开等基础数学知识。
- 先修内容:Python编程语言
- 难度系数:中
理论部分
- 机器学习介绍:机器学习是什么,怎么来的,理论基础是什么,为了解决什么问题。
- 机器学习分类:
- 按学习方式分:有监督、无监督、半监督
- 按任务类型分:回归、分类、聚类、降维 生成模型与判别模型
- 机器学习方法三要素:
- 模型
- 策略:损失函数
- 算法:梯度下降法、牛顿法、拟牛顿法
- 模型评估指标:R2、RMSE、accuracy、precision、recall、F1、ROC、AUC、Confusion Matrix
- 复杂度度量:偏差与方差、过拟合与欠拟合、结构风险与经验风险、泛化能力、正则化
- 模型选择:正则化、交叉验证
- 采样:样本不均衡
- 特征处理:归一化、标准化、离散化、one-hot编码
- 模型调优:网格搜索寻优、随机搜索寻优
理论部分
- 模型建立:线性回归原理、线性回归模型
- 学习策略:线性回归损失函数、代价函数、目标函数
- 算法求解:梯度下降法、牛顿法、拟牛顿法等
- 线性回归的评估指标
- sklearn参数详解
练习部分
- 基于线性回归的房价预测问题
- 利用
sklearn解决回归问题 sklearn.linear_model.LinearRegression
理论部分
- 逻辑回归与线性回归的联系与区别
- 模型建立:逻辑回归原理、逻辑回归模型
- 学习策略:逻辑回归损失函数、推导及优化
- 算法求解:批量梯度下降
- 正则化与模型评估指标
- 逻辑回归的优缺点
- 样本不均衡问题
- sklearn参数详解
练习部分
- 利用
sklearn解决分类问题 sklearn.linear_model.LogisticRegression- 利用梯度下降法将相同的数据分类,画图和sklearn的结果相比较
- 利用牛顿法实现结果,画图和sklearn的结果相比较,并比较牛顿法和梯度下降法迭代收敛的次数
理论部分
- 特征选择:信息增益(熵、联合熵、条件熵)、信息增益比、基尼系数
- 决策树生成:ID3决策树、C4.5决策树、CART决策树(CART分类树、CART回归树)
- 决策树剪枝
- sklearn参数详解
练习部分
- 利用
sklearn解决分类问题和回归预测。 sklearn.tree.DecisionTreeClassifiersklearn.tree.DecisionTreeRegressor
理论部分
- 相关概念
- 无监督学习
- 聚类的定义
- 常用距离公式
- 曼哈顿距离
- 欧式距离
- 闵可夫斯基距离
- 切比雪夫距离
- 夹角余弦
- 汉明距离
- 杰卡德相似系数
- 杰卡德距离
- K-Means聚类:聚类过程和原理、算法流程、算法优化(k-means++、Mini Batch K-Means)
- 层次聚类:Agglomerative Clustering过程和原理
- 密度聚类:DBSCAN过程和原理
- 谱聚类:谱聚类原理(邻接矩阵、度矩阵、拉普拉斯矩阵、RatioCut、Ncut)和过程
- 高斯混合聚类:GMM过程和原理、EM算法原理、利用EM算法估计高斯混合聚类参数
- sklearn参数详解
练习部分
- 利用
sklearn解决聚类问题。 sklearn.cluster.KMeans
理论部分
- 相关概念
- 生成模型
- 判别模型
- 朴素贝叶斯基本原理
- 条件概率公式
- 乘法公式
- 全概率公式
- 贝叶斯定理
- 特征条件独立假设
- 后验概率最大化
- 拉普拉斯平滑
- 朴素贝叶斯的三种形式
- 高斯型
- 多项式型
- 伯努利型
- 极值问题情况下的每个类的分类概率
- 下溢问题如何解决
- 零概率问题如何解决
- sklearn参数详解
练习部分
- 利用
sklearn解决聚类问题。 sklearn.naive_bayes.GaussianNB
开源内容:https://github.com/datawhalechina/team-learning-data-mining/tree/master/RentForecast
以真实竞赛的数据,真实比赛场景为依托,开始一场模拟房租预测比赛。
赛题地址:https://2019ai.futurelab.tv/contest_detail/3#contest_des
- 贡献人员:胡联粤,四月,李威、杨煜、张浩、杨冰楠
- 学习周期:12天,每天平均花费时间3小时-5小时不等,根据个人学习接受能力强弱有所浮动。
- 学习形式:理论学习 + 练习
- 人群定位:Python基本掌握,能够调包实现算法,对数据有一定的分析处理能力。
- 先修内容:Python编程语言
- 难度系数:中
每一步都要认真完成,附上代码,最终效果截图
认识数据
- 了解比赛的背景
- 分类问题还是回归问题
- 熟悉比赛的评分函数
对比赛数据做EDA
- 缺失值分析
- 特征值分析
- 是否有单调特征列(单调的特征列很大可能是时间)
- 特征nunique分布
- 统计特征值出现频次大于100的特征
- Label分布
- 不同的特征值的样本的label的分布
每一步都要认真完成,附上代码,最终效果截图
缺失值分析及处理
- 缺失值出现的原因分析
- 采取合适的方式对缺失值进行填充
异常值分析及处理
- 根据测试集数据的分布处理训练集的数据分布
- 使用合适的方法找出异常值
- 对异常值进行处理
深度清洗
- 分析每一个communityName、city、region、plate的数据分布并对其进行数据清洗
使用3种以上特征选择的方法,附上代码,最终效果截图
特征工程
数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。那特征工程到底是什么呢?顾名思义,其本质是一项工程活动,目的是最大限度地从原始数据中提取特征以供算法和模型使用。so,想要获得一个比较好的分数,特征工程是十分重要的。那么数据清洗之后,特征工程该如何下手呢?由于不同的业务特征工程千差万别,在这里,只给一些思路,一些具体的特征工程方法,大家自己摸索。
- 房间总数
- 根据房型信息抽取出更细的信息,然后可以组合
- 每平方均价
- 根据租房信息可以求得每平方的均价
- 根据小区信息groupby
- 同一个小区的租房信息相差不大,可以根据小区
- 聚类特征
- 使用sklearn.mixture.GaussianMixture做聚类特征
- Word2vec特征
- 将类别特征使用w2v构建特征(思路:将每一个样本的类别特征够造成一个句子,然后使用word2vec提取特征之间的相关关系)
- OneHotEncoder、labelencoder
- 过大量级值取log平滑(针对线性模型有效)
特征选择
- Filter
- 相关系数法
- 卡方检验
- Wrapper
- 递归特征消除法(RFE)
- Embedded
- 基于惩罚项的特征选择法
- 基于树模型的特征选择法
- baseline
- 任选一个模型套用,得到baseline。对比任务二使用的模型结果的得分情况。
每一步都要认真完成,附上代码,最终效果截图
模型选择
如果你不熟悉各个算法模型的适用数据,那么就去尝试吧!然后选取效果最好的模型,当然这个是基于你已经做好一套特征工程之后,比赛中常用的模型有GBDT,XGB,LGB,CatBoost等等。
选取两个模型,学习Sklearn包相关参数。
模型调优
使用网格搜索进行模型调参,并记录每个模型的最优参数
结果对比
任选一个模型套用,得到 baseline 对比任务三使用的模型结果的得分情况。
任选三个模型融合的方法进行融合。附上代码,最终效果截图
模型融合
尝试多种模型融合的方案
- stacking
- 简单加权融合
- blending
- boosting
- bagging
- 将多个模型结果再放入模型中预测
- ……以及你能想到和借鉴的模型融合方法
结果对比
对比任务四使用的模型结果的得分情况。
以赛方最后给的答辩模板为主线整理比赛思路,模拟比赛答辩环节,进行比赛整理。
Part1:参赛队成员简介
这个由于是模拟比赛所以这个部分可以不写哦
Part2:参赛作品概述
Part3:关键技术阐述
数据清洗、特征工程、模型、模型融合,并强调对比赛提分最有帮助的部分
Part4:探索与创新
写明做的与众不同的创新点
Part5:实施与优化过程
在过程中尝试过的方法都可以提及并总结
Part6:其它
有其他需要补充的可以写在这个部分,因为比赛是和企业合作,并具有实际意义的比赛,所以强调你的代码模型的实际意义,商业价值都会在答辩环节有帮助哦。
- 注册 CSDN 或 Github 账户。
- 按照任务安排进行学习,完成后写学习笔记Blog。
- 在每次任务截止之前在群内打卡(发Blog链接),遇到问题在群内讨论。
- 未按时打卡的同学视为自动放弃,被抱出学习群。
有关Datawhale组队学习的开源内容如下:
本次组队学习的 PDF 文档可到Datawhale的知识星球下载:

