The topic is free to choose, but below you will find a (somewhat outdated) list of possible topics for projects or related-work research. Additionally, you can look at the intro slides for some inspiration!
Please Note: Your choice is not limited to the topics below!
The goal of this project is to investigate a recent trend in deep learning: combining language and image models. The topic is about systems that can convert text to images and vice versa.
| A (very) abstract penguin | Illustration of a Fox |
|---|---|
 |
 |
Light Fields (LFs) are an alternative way of storing and recording scenes. In comparison to conventional images, light fields support processing techniques such as refocusing (see Figure above), changing the perspective, and novel view synthesis. Light fields can be imagined as a set of images from multiple perspectives. Therefore, processing and viewing LFs leads to large amounts of data that need to be processed and rendered efficiently. One way of overcoming this limitation is to convert them into a 3D representation as done by NeRF. Neural Radiance Fields (NeRF) is a new technique for representing scenes that allow novel view synthesis (visualizing viewpoints that have not been recorded before) and various other effects. The technique works with a set of images as input (a light field).

With recent advances in Computer Vision, it is now possible to track people in a simple video stream without specialized hardware adn without markers on the body. The systems retrieve a 3D model of the body and its movement.

The goal of this project is to animate the faces of people in still photos. Your algorithm should produce a realistic depiction of how a person from a photo could have moved and looked if they were captured in a short video clip. There might be several possible algorithms to tackle the project. Nevertheless, I believe that only a deep learning method will produce convincing results.
| Still Image | Face Animation |
|---|---|
 |
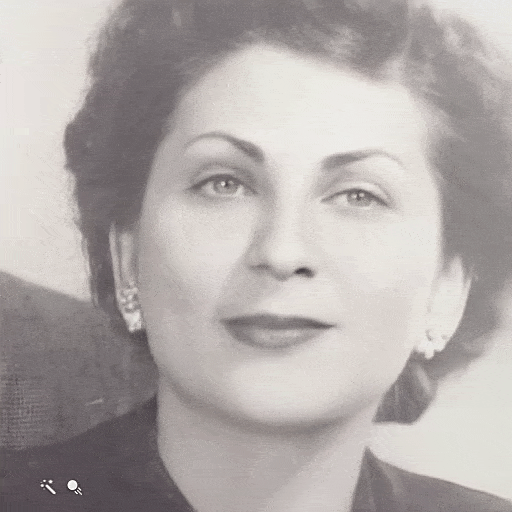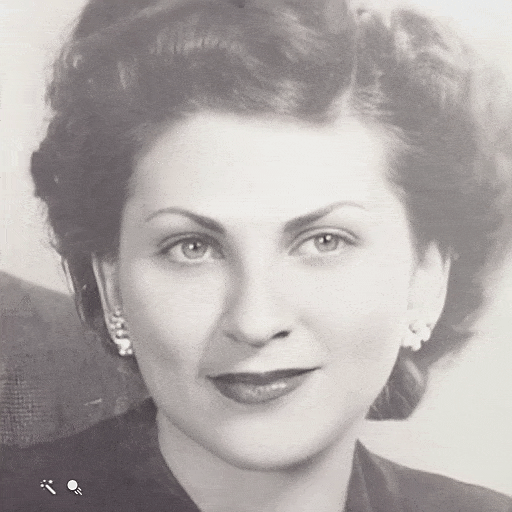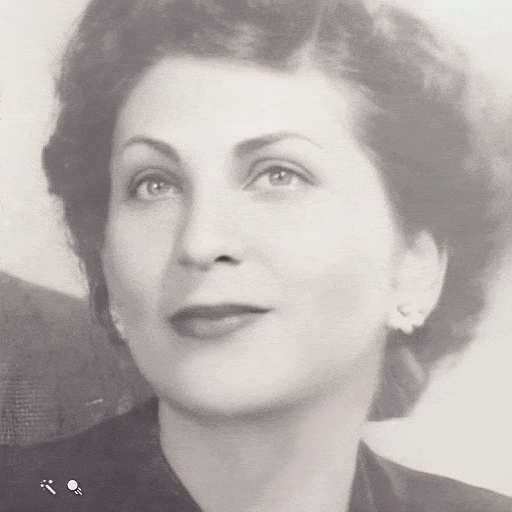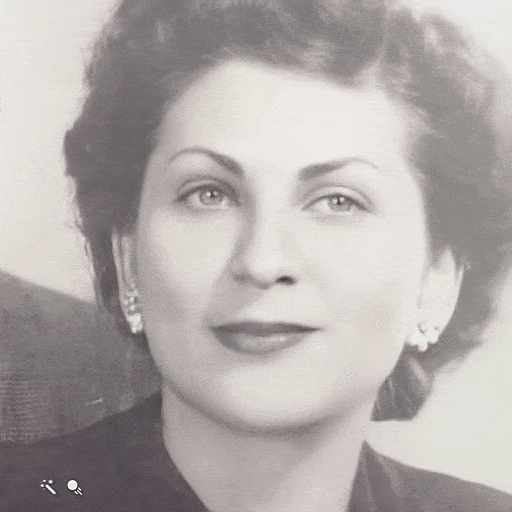 |
Don't apply this technique to humans but other moving objects. For example, trees that move in the wind, or animals such as cats and dogs. Note, however, that it might be hard to find useful training data for other objects.
- Inspiration from myheritage.com
- Possible dataset for training YouTube Faces DB
The goal of this project is to work on computer-vision-based navigation on the FH campus. Based on a picture at the campus your algorithm estimates the position of the camera as precisely as possible. An optional bonus feature is a navigation system that tells you where to go if you are looking for a specific room.

If you are not at the campus (e.g., due to Corona), use (parts of) your hometown to showcase your algorithm.
The goal of this project is to generate an algorithm that detects sign language and the corresponding letters based on a sequence of input images.
Optionally, output the detection with some text-to-speech software.

- Communicating in sign languages does not rely on a simple alphabet, but uses symbols for phrases and words. So in reality it is much more complex than just recognizing 26 letters of the alphabet. Try to work on a complex sign language recognition system.
- Instead of recognizing sign language, work on a sign language generator. So your method creates pictures of hands given an input (letters or words). Note that, generating sign language images will be harder than recognizing them.
- Various available sign language datasets: http://facundoq.github.io/guides/sign_language_datasets/slr
- Simple dataset (only the alphabet): https://www.kaggle.com/datamunge/sign-language-mnist
Develop an algorithm that gets a greyscale image as input and outputs a realistic color image without any user intervention. Current state-of-the-art colorization techniques rely on deep learning.

http://6.869.csail.mit.edu/fa19/projects/colorization_proposal.pdf
The goal of this project is to develop an algorithm that recognizes scenes or objects in an image. There are three options (from easy to hard):
- Image recognition classifies an entire image (e.g., an image with a snowy mountain peak gets classified as a mountain).
- Object detection detects and localizes objects in an image. The position of detected objects is usually returned as a bounding box.
- Scene segmentation, or pixel-wise dense labeling, aims to give every pixel a label, which is more fine-grained than image-level recognition or object detection.
Numerous datasets and a vast literature for these problems exists.

http://6.869.csail.mit.edu/fa19/projects/segmentation_proposal.pdf
- Super Resolution: Given a low-resolution input image, the algorithm computes a convincing high-resolution output image (advanced: work on videos).
- Image Matting: The algorithm operates on an input image and separates it into fore- and background (e.g., an image of a face will be separated into face and background; can be very useful for compositing).
- Biometrics: Use an iris pattern, fingerprints, facial patterns, or some other feature, to reliably identify a person.
- Image Style Transfer: Transfer the style of an image to another image. For example, this technique can be used to convert paintings into pictures and vice versa.
- Time Machine: vary the age of a person in an image (similar to existing Snapchat filters).
- 3D reconstruction: reconstruct a geometrical representation (e.g., a point cloud) from a sequence of input images (advanced: only use one image and try to estimate depth).
- A list of other project ideas (from MIT): http://6.869.csail.mit.edu/fa19/project.html
- Resources, such as image databases and books (from MIT): http://6.869.csail.mit.edu/fa19/materials.html
- YouTube channels that discuss recent science breakthroughs (mostly deep learning, such as Yannic Kilcher or tow minute papers )